Benchmarks
2,500+ LLM evaluations across 11 models, 4 providers, and 50+ independent test runs.
No model has ever been trained on GCF. Every model reads it better than the formats they were trained on.
| Generic Profile (500 orders) | Graph Profile (500 symbols) | |
|---|---|---|
| GCF | 100% on every frontier model | 91.2% (10 models) |
| TOON | weakest format consistently | 68.8% |
| JSON | GCF avg >= JSON on every model | 54.1% |
| GCF | TOON | JSON | |
|---|---|---|---|
| Token efficiency (16 datasets) | wins 15/16 | wins 1/16 | wins 0/16 |
| Generation (28 runs, 11 models) | 5/5 | 1.0/5 | 5.0/5 |
| 43,000,000,000+ round-trips | 0 failures |
Five benchmark suites, four providers (Anthropic, OpenAI, Google, Mistral), zero training:
- Generic comprehension: 500-order nested data, 27 runs, 11 models. GCF 100% on every frontier model.
- Graph comprehension: 500-symbol code graphs, 25 runs, 10 models. GCF 91.2% where JSON drops to 54.1%.
- Scale test: At 1000 records, JSON doesn't fit. GCF is the only format that works on 200K context models.
- Token efficiency: 16 real-world datasets. GCF wins 15/16 vs TOON, 29% fewer overall.
- Generation: Every frontier model produces valid GCF. TOON's decoder rejects output from 7/9 models.
- Tokenizer analysis: 43 tokenizers, 20 providers. GCF pipe merge rate 0.47% vs JSON 8.17% vs TOON 32.91%. JSON's grammar merges with field names at the vocabulary level on a third of the LLM market.
All results reproducible.
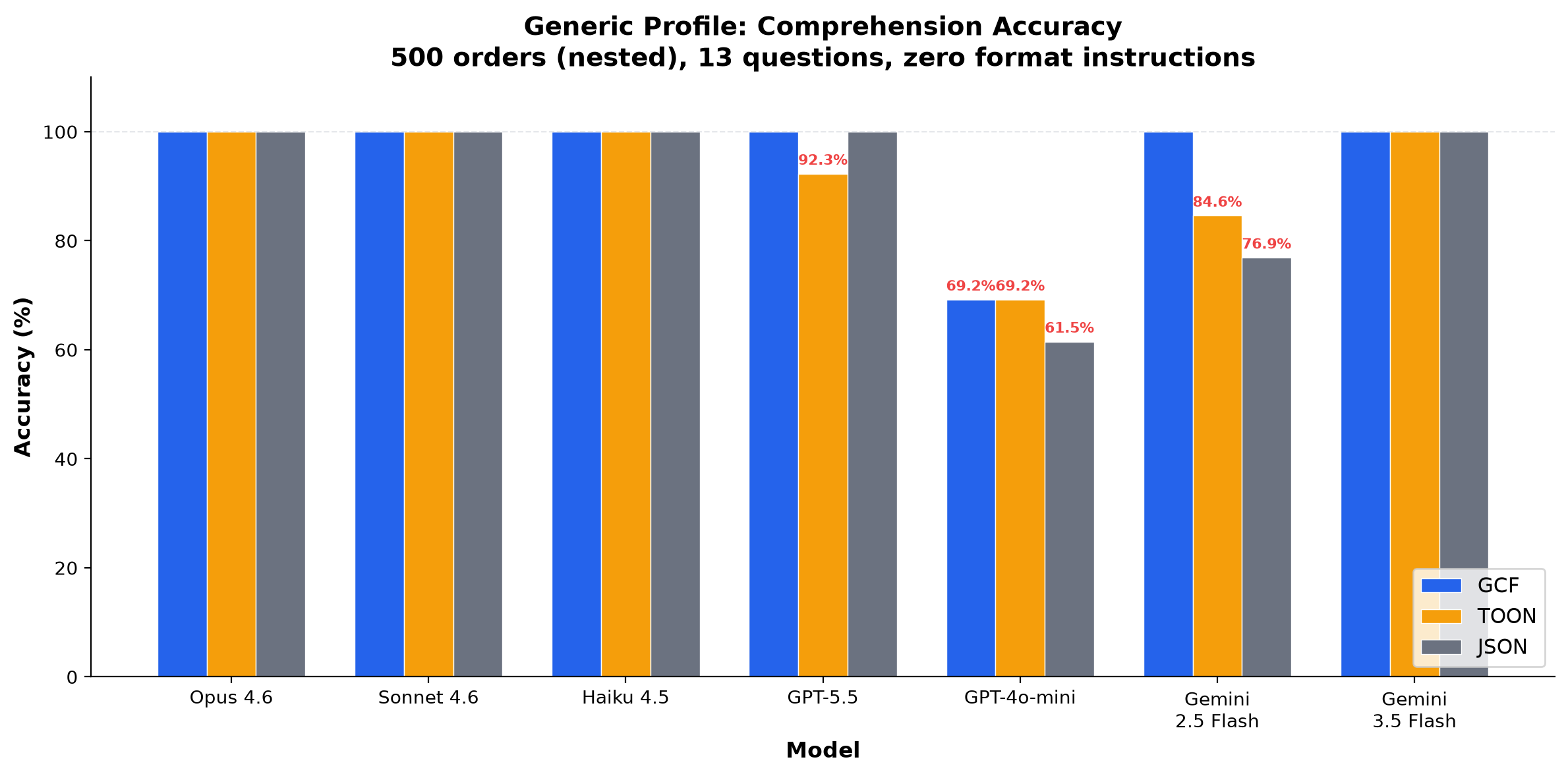
Generic Profile: Standard Workloads
500 orders with nested customer objects and line items. 13 structured extraction questions. Zero format instructions. Deterministic answers, no LLM judge.
This is what most MCP tool responses look like: arrays of objects with nested metadata. The "normal" workload.
| Model | Provider | Runs | GCF avg | TOON avg | JSON avg |
|---|---|---|---|---|---|
| Claude Opus 4.6 | Anthropic | 2 | 100% | 100% | 100% |
| Claude Sonnet 4.6 | Anthropic | 3 | 100% | 97.4% | 100% |
| Claude Haiku 4.5 | Anthropic | 4 | 100% | 100% | 100% |
| GPT-5.5 | OpenAI | 2 | 100% | 96.2% | 100% |
| Gemini 2.5 Pro | 3 | 100% | 100% | 100% | |
| Gemini 3.1 Pro Preview | 1 | 100% | 100% | 100% | |
| Gemini 3.5 Flash | 2 | 100% | 100% | 100% | |
| Gemini 2.5 Flash | 4 | 95.0% | 85.1% | 74.0% | |
| Mistral Medium 3.5 | Mistral | 4 | 82.7% | 76.9% | 82.0% |
| Mistral Large 3 | Mistral | 1 | 69.2% | 69.2% | 69.2% |
| GPT-4o-mini | OpenAI | 1 | 69.2% | 69.2% | 61.5% |
27 runs, 11 models, 4 providers. Frontier models (Opus, Sonnet, Haiku, GPT-5.5, Gemini 2.5 Pro, Gemini 3.1 Pro, Gemini 3.5 Flash) achieve 100% GCF on every run. GCF averages equal or better than JSON on every model. TOON is consistently the weakest format.
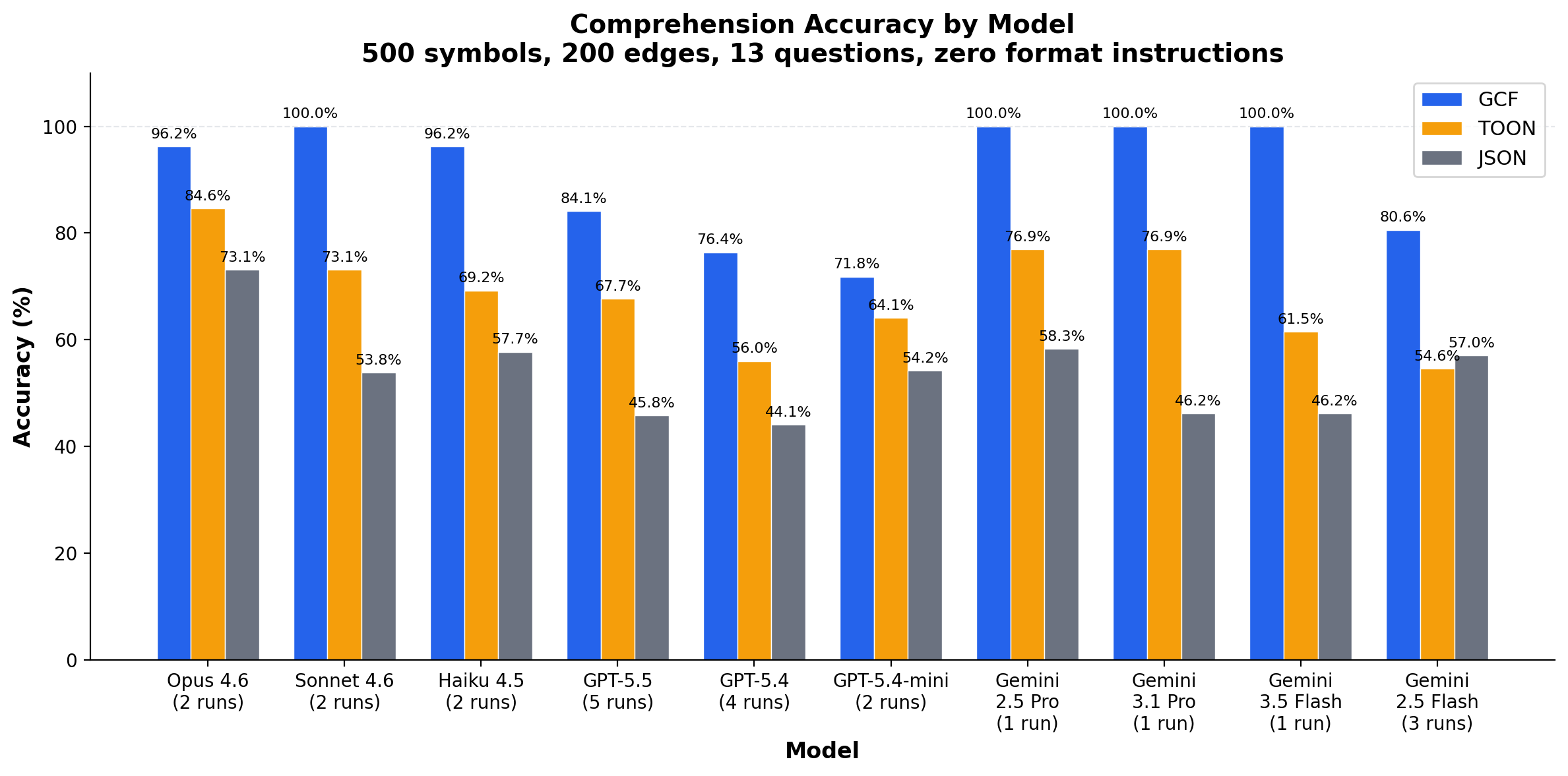
Graph Profile: Under Structural Stress
500 symbols, 200 edges, zero format instructions. Code intelligence data with cross-references, distance groups, and provenance chains. This is the hard case: structurally complex data that tests whether a format scales.
| Model | Runs | GCF avg | TOON avg | JSON avg |
|---|---|---|---|---|
| Claude Opus 4.6 | 2 | 96.2% | 88.5% | 73.1% |
| Claude Sonnet 4.6 | 2 | 100% | 73.1% | 53.8% |
| Claude Haiku 4.5 | 2 | 96.2% | 69.2% | 57.7% |
| GPT-5.5 | 5 | 84.1% | 67.7% | 45.8% |
| GPT-5.4 | 4 | 78.0% | 56.0% | 44.1% |
| GPT-5.4-mini | 2 | 71.8% | 64.1% | 54.1% |
| Gemini 2.5 Pro | 2 | 100% | 78.5% | 65.5% |
| Gemini 3.1 Pro | 1 | 100% | 76.9% | 46.2% |
| Gemini 3.5 Flash | 1 | 100% | 61.5% | 46.2% |
| Gemini 2.5 Flash | 4 | 85.5% | 52.5% | 54.3% |
25 runs, 10 models, 3 providers. GCF wins 24, ties 1, loses 0.
When an agent receives data in JSON at this scale, it gets the wrong answer 46% of the time. With TOON, 32% of the time. With GCF, 10%.
Why GCF wins on complex data
GCF encodes answers structurally. "How many related symbols?" is answered by the section header ## related [167]. TOON and JSON force the model to scan 500 rows and count. The result: GCF errors are off by 1-2 (precision), TOON/JSON errors are off by 50-140 (comprehension failure).
See the full failure taxonomy for the complete analysis.
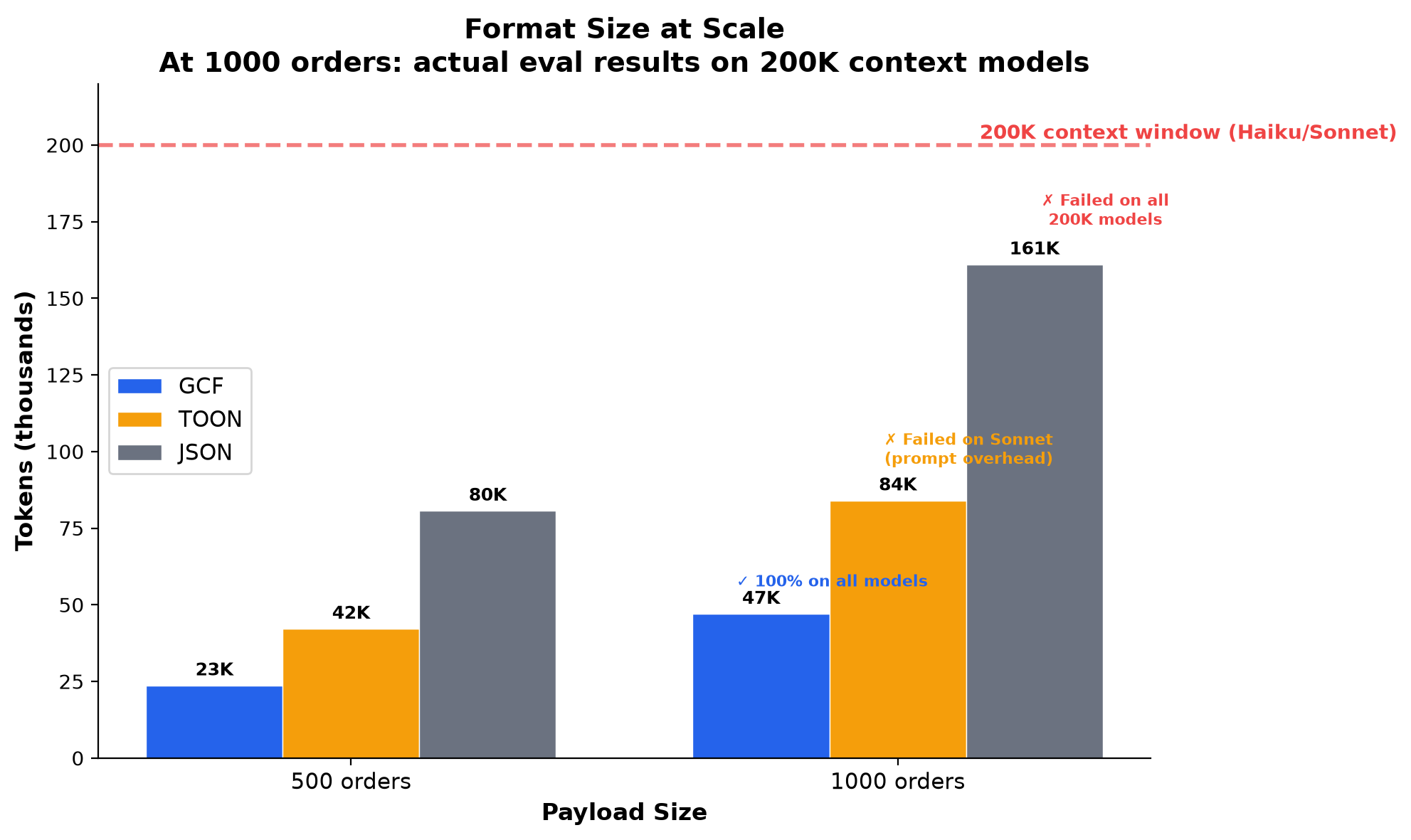
Scale Test: 1000 Orders
At production scale, format choice determines whether the task is possible at all.
| Model | Context | GCF (47K) | TOON (84K) | JSON (161K) |
|---|---|---|---|---|
| Claude Haiku 4.5 | 200K | 100% (13/13) | 100% (13/13) | IMPOSSIBLE |
| Claude Sonnet 4.6 | 200K | 92.3% (12/13) | IMPOSSIBLE | IMPOSSIBLE |
| Claude Opus 4.6 | 1M | 100% (13/13) | 100% (13/13) | 100% (13/13) |
| GPT-5.5 | - | 100% (6/6) | 100% (5/5) | 100% (6/6) |
JSON at 1000 records consumes 161K tokens. On 200K context models, this exceeds usable context and the task becomes impossible. TOON at 84K also exceeds the effective limit on Sonnet.
GCF encodes the same data in 47K tokens (71% smaller than JSON). This means:
- On 200K models: GCF is the only format that reliably fits
- On 1M models: all formats work, but GCF costs 71% less per API call
- In agent loops: GCF leaves 150K+ tokens for conversation history, tool schemas, and reasoning
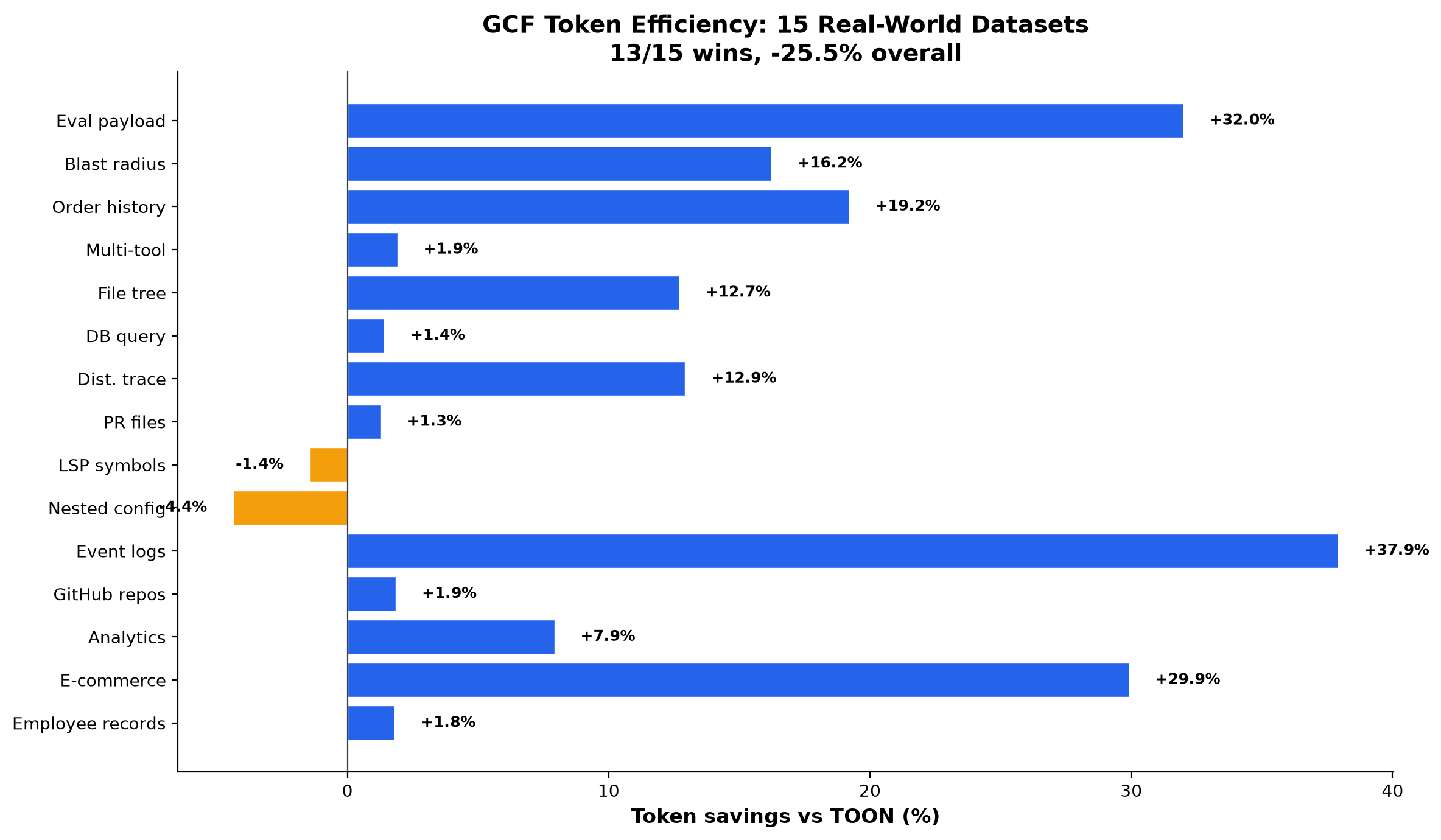
Token Efficiency: 16 Datasets
16 real-world datasets representing actual LLM tool response payloads. Same tokenizer (o200k_base), deterministic data, spec-compliant encoders.
| # | Dataset | GCF | TOON | GCF vs TOON |
|---|---|---|---|---|
| 1 | Employee records (flat) | 49,061 | 49,966 | -1.8% |
| 2 | E-commerce orders (nested) | 50,343 | 73,246 | -31.3% |
| 3 | Analytics time-series | 8,404 | 9,127 | -7.9% |
| 4 | GitHub repositories | 8,599 | 8,744 | -1.7% |
| 5 | Event logs (semi-uniform) | 95,193 | 154,032 | -38.2% |
| 6 | Nested config | 617 | 618 | -0.2% |
| 7 | LSP symbol search | 5,442 | 5,365 | +1.4% |
| 8 | PR file changes | 2,623 | 2,657 | -1.3% |
| 9 | Distributed trace | 4,318 | 4,959 | -12.9% |
| 10 | Database query results | 17,716 | 17,969 | -1.4% |
| 11 | File tree + diagnostics | 6,018 | 6,894 | -12.7% |
| 12 | Multi-tool composite | 3,131 | 3,192 | -1.9% |
| 13 | Order history (shared schemas) | 13,295 | 16,454 | -19.2% |
| 14 | Blast radius response | 6,561 | 7,831 | -16.2% |
| 15 | Kubernetes pod status | 40,097 | 60,603 | -33.8% |
| 16 | Enterprise org hierarchy | 222,196 | 330,486 | -32.8% |
| TOTAL | 533,614 | 752,143 | -29.0% |
GCF wins 15/16 vs TOON. TOON's one win: LSP symbols (77 tokens, 1.4%, tokenizer artifact where the pipe delimiter tokenizes slightly worse than comma on this specific data shape).
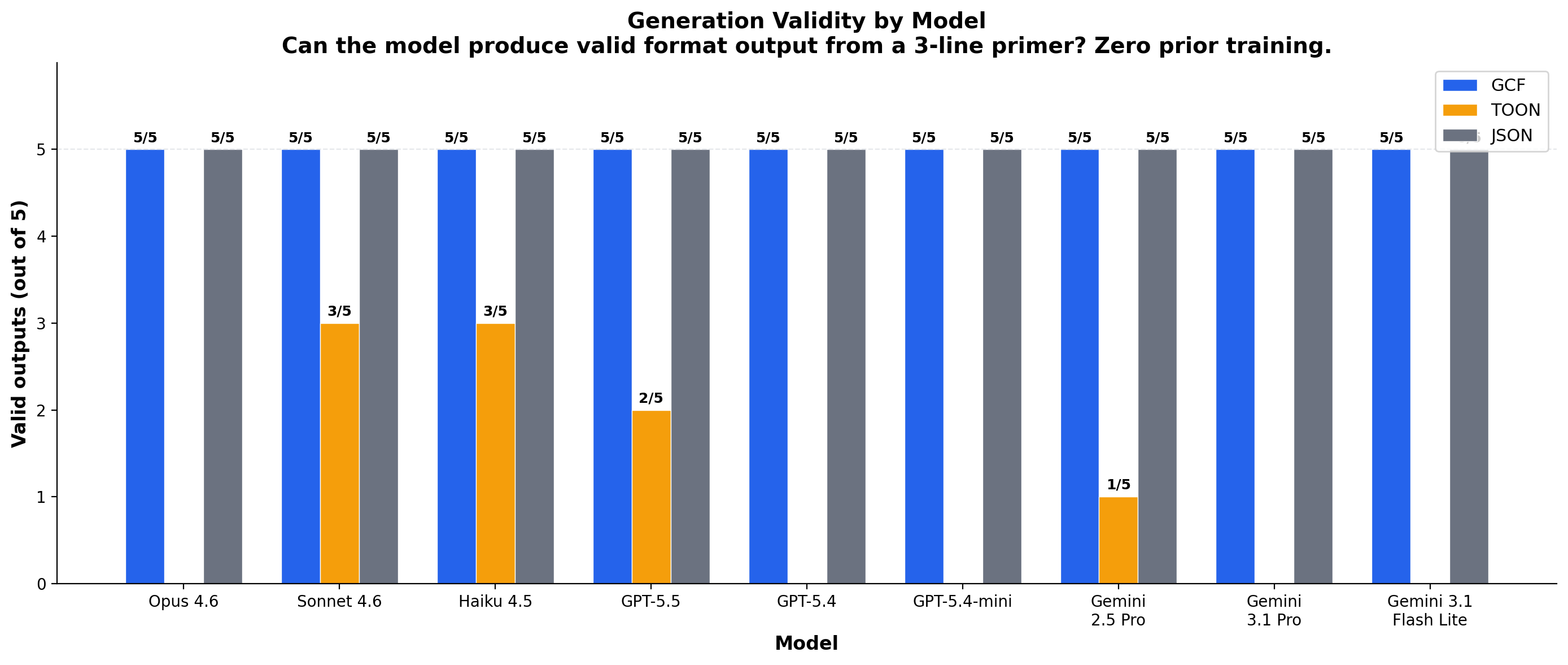
Generation: Can LLMs Write It?
The model is given a natural-language description and a 3-line format primer. It must produce valid, decoder-parseable output. Tested at 5, 10, 20, 50, and 100 symbols.
| Model | GCF | TOON | JSON |
|---|---|---|---|
| Claude Opus 4.6 | 5/5 | 0/5 | 5/5 |
| Claude Sonnet 4.6 | 5/5 | 2-3/5 | 5/5 |
| Claude Haiku 4.5 | 5/5 | 1-3/5 | 5/5 |
| GPT-5.5 | 4-5/5 | 1-2/5 | 5/5 |
| GPT-5.4 | 5/5 | 0/5 | 5/5 |
| GPT-5.4-mini | 5/5 | 0/5 | 5/5 |
| Gemini 2.5 Pro | 5/5 | 1/5 | 5/5 |
| Gemini 3.1 Pro | 5/5 | 0/5 | 5/5 |
| Gemini 3.1 Flash Lite | 4-5/5 | 0/5 | 4-5/5 |
| Gemini 3.5 Flash | 3/5 | 1/5 | 3/5 |
| Gemini 2.5 Flash | 2-4/5 | 0-4/5 | 0-3/5 |
11 models, 3 providers. GCF wins or ties every model; on the two mid-tier Flash models where GCF drops below 5/5, JSON and TOON drop further (GCF 3.0 vs JSON 1.7 vs TOON 1.3 on Gemini 2.5 Flash). GCF is the only format every frontier model can produce. TOON's official decoder rejects output on 7 of 9 models. The format's flat tabular design encodes semantic categories as integers, forcing a mapping no model performs unprompted.
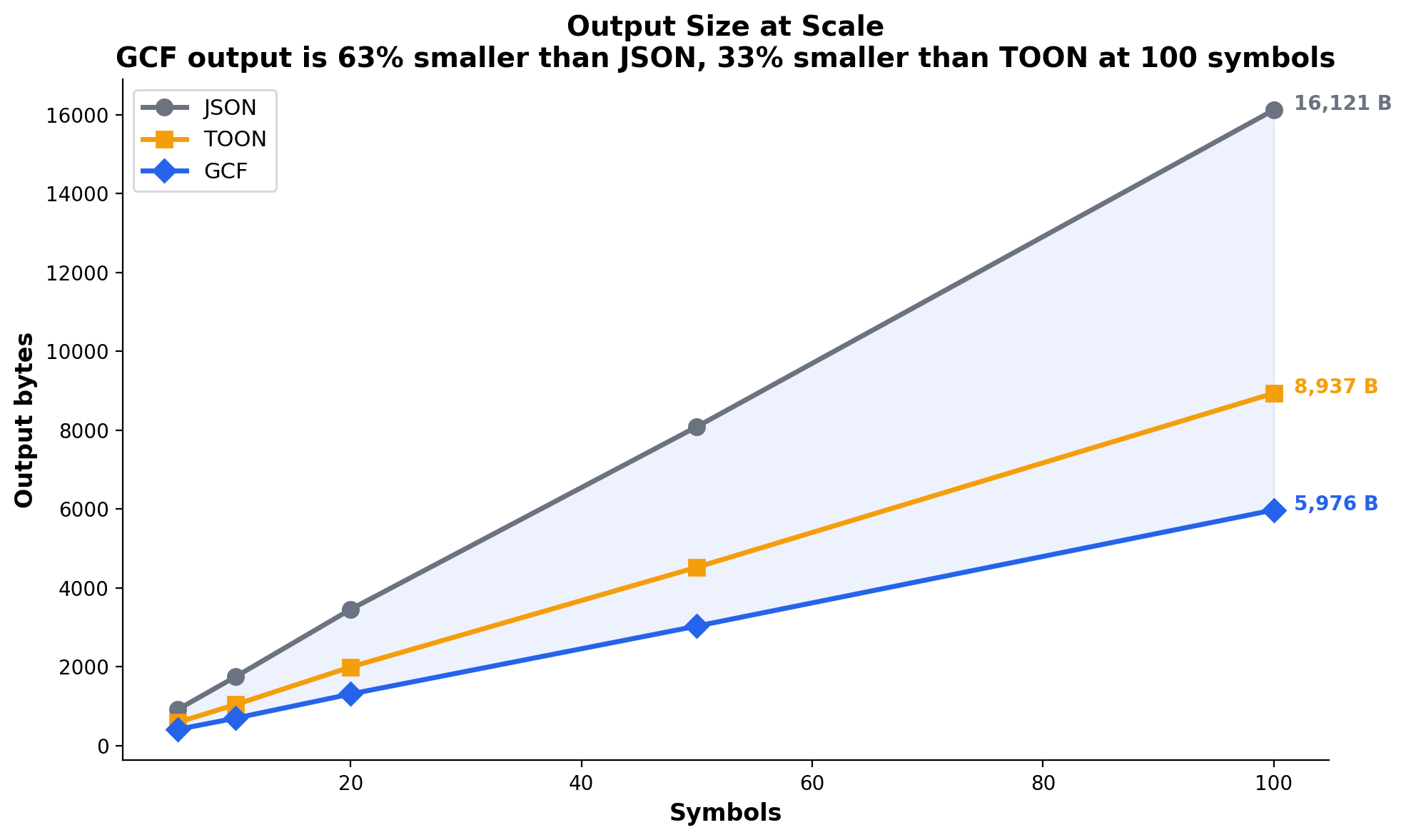
GCF output is 63% smaller than JSON and 33% smaller than TOON at 100 symbols. Every output token costs money.
Reproduce
All evals are in gcf-go/eval. All raw logs are in eval/results.
git clone https://github.com/blackwell-systems/gcf-go
cd gcf-go/eval
# Generic profile comprehension
GOWORK=off EVAL_FORMATS=gcf,json,toon EVAL_BACKEND=cli EVAL_MODEL=haiku EVAL_NUM_ORDERS=500 go test -run TestGenericComprehension -v -timeout 0
# Graph profile comprehension
GOWORK=off go test -run TestComprehension -v -timeout 0
EVAL_BACKEND=openai OPENAI_API_KEY=... EVAL_MODEL=gpt-5.5 GOWORK=off go test -run TestComprehension -v -timeout 0
EVAL_BACKEND=google GOOGLE_API_KEY=... EVAL_MODEL=gemini-2.5-flash GOWORK=off go test -run TestComprehension -v -timeout 0
# Generation
GOWORK=off go test -run "TestGeneration$|TestGenerationTOON|TestGenerationJSON" -v -timeout 0
# Token efficiency (16 datasets)
git clone https://github.com/blackwell-systems/toon-benchmark
cd toon-benchmark
node --experimental-strip-types benchmarks/scripts/token-efficiency-benchmark.tsFor detailed failure analysis, error taxonomy, and per-run data, see the full eval results.