Session Deduplication
In multi-turn LLM tool interactions, the same symbols appear across multiple responses. A code intelligence tool queried about AuthMiddleware will return it in the first response, and likely again in follow-up queries about related functions.
JSON and every other format retransmit the full declaration every time. GCF's graph profile tracks what's been sent and replaces known symbols with bare references.
Session deduplication is graph-specific: it relies on the graph profile's local IDs and bare references. The generic profile reaches the same across-session compression through delta encoding, which re-sends only the rows that changed. The two are parallel multi-turn mechanisms, one per profile.
Measured savings
Benchmarked across 8 production tokenizers (GPT-4o, Claude, LLaMA 3.1, Gemma 2, Mistral 7B, Qwen 2.5, DeepSeek V3, Phi-4) on 500-symbol payloads with realistic overlap patterns:
| Encoding layer | Savings vs JSON | Incremental |
|---|---|---|
| GCF format alone | 63.8% | baseline |
| + Session dedup | 80.8% | +17.1pp |
| + Delta (stacked) | 88.3% | +7.5pp |
On a 10-call session: 94.4% cumulative savings vs JSON. By call 10, each response costs 171 tokens vs 29,072 for JSON (99.4% per-call savings).
The problem
Call 1: LLM asks "What calls AuthMiddleware?"
Response: 15 symbols, 8 edges → 2,100 tokensCall 2: LLM asks "What does NewServer do?"
Response: 18 symbols (12 overlap with call 1), 10 edges → 2,400 tokensCall 3: LLM asks "Show me the auth flow"
Response: 22 symbols (18 overlap), 14 edges → 2,800 tokensWith JSON, each response is a full retransmission. Total: 7,300 tokens.
The solution: session state
With GCF sessions, previously-sent symbols become bare references:
@7 # previously transmittedThe LLM already has @7 in its context window from the prior response. No need to resend the qualified name, kind, score, or provenance.
Call 1: Full declarations (same as non-session)
GCF profile=graph tool=context_for_task budget=5000 tokens=2100 symbols=15 edges=12
## targets
@0 fn pkg.AuthMiddleware 0.78 lsp_resolved
@1 fn pkg.ValidateToken 0.72 lsp_resolved
...Call 2: 12 of 18 symbols are bare refs
GCF profile=graph tool=context_for_task budget=5000 tokens=800 symbols=18 edges=14 session=true
## targets
@0 # previously transmitted
@1 # previously transmitted
@2 fn pkg.NewServer 0.85 lsp_resolved
...Call 3: 18 of 22 symbols are bare refs
GCF profile=graph tool=context_for_task budget=5000 tokens=400 symbols=22 edges=18 session=true
## targets
@0 # previously transmitted
@1 # previously transmitted
@2 # previously transmitted
@3 fn pkg.AuthFlow 0.91 lsp_resolved
...How it works
- Create a session when the conversation starts
- After each encode, the session records which symbols were transmitted
- On subsequent encodes, symbols already in the session become bare refs
- The
session=trueheader flag signals that bare refs are present
The session is server-side state. The LLM doesn't need to do anything special; it sees the full context from prior responses in its conversation window.
Implementation
from gcf import encode_with_session, Session, Payload, Symbol
sess = Session()
# First call: full declarations
out1 = encode_with_session(payload1, sess)
# Second call: overlapping symbols become bare refs
out2 = encode_with_session(payload2, sess)
# Check session state
print(sess.size()) # number of tracked symbols
print(sess.transmitted("pkg.Auth")) # True/False
sess.reset() # clear for new conversationimport { encodeWithSession, Session } from '@blackwell-systems/gcf';
const sess = new Session();
// First call: full declarations
const out1 = encodeWithSession(payload1, sess);
// Second call: overlapping symbols become bare refs
const out2 = encodeWithSession(payload2, sess);
// Check session state
console.log(sess.size());
console.log(sess.transmitted('pkg.Auth'));
sess.reset();sess := gcf.NewSession()
// First call: full declarations
out1 := gcf.EncodeWithSession(payload1, sess)
// Second call: overlapping symbols become bare refs
out2 := gcf.EncodeWithSession(payload2, sess)
// Check session state
fmt.Println(sess.Size())
fmt.Println(sess.Transmitted("pkg.Auth"))
sess.Reset()Thread safety
The Session type is thread-safe in all implementations:
- Go:
sync.Mutex - Python:
threading.Lock - Rust:
Mutex<SessionInner> - Swift:
NSLock - Kotlin:
@Synchronized - TypeScript: single-threaded (safe by default)
Multiple tool handlers can encode concurrently within the same session.
When to use sessions
- MCP servers with multi-turn conversations (the primary use case)
- Chat-based tools where the LLM makes sequential queries
- Any interaction where the same symbols appear across multiple responses
When NOT to use sessions
- Single-shot tool calls (no prior context to reference)
- Different users or conversations (don't share sessions across contexts)
- When the LLM's context window has been truncated (bare refs to symbols outside the window will confuse the model)
Comprehension validation
Session dedup was validated on Gemini 2.5 Pro and Gemini 2.5 Flash:
- Attribute resolution (kind, provenance, score) through bare refs: 100% on both models
- Depth tolerance: zero degradation through 15 calls (31 messages) on Gemini 2.5 Pro
- Session dedup matches full retransmission accuracy on every test
- Edge direction: Flash reverses
<arrow direction; Pro reads it correctly
Full eval results: Session Dedup Eval
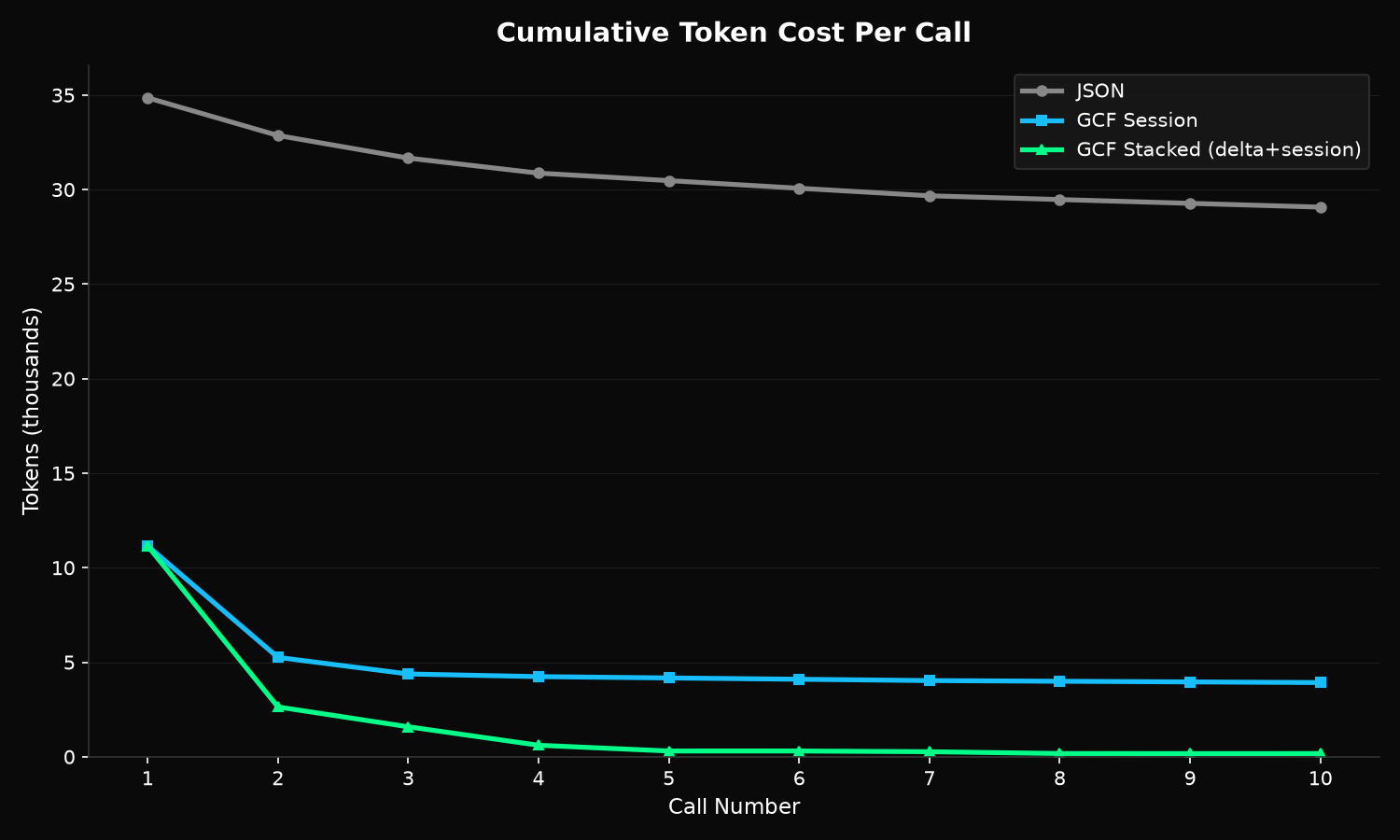
Token savings curve (measured)
Benchmarked on GPT-4o tokenizer, 500-symbol payloads:
| Call # | JSON tokens | Session tokens | Stacked tokens | Session/JSON | Stacked/JSON |
|---|---|---|---|---|---|
| 1 | 34,854 | 11,154 | 11,154 | 68.0% | 68.0% |
| 2 | 32,862 | 5,257 | 2,636 | 84.0% | 92.0% |
| 3 | 31,666 | 4,380 | 1,587 | 86.2% | 95.0% |
| 5 | 30,474 | 4,170 | 305 | 86.3% | 99.0% |
| 10 | 29,072 | 3,925 | 171 | 86.5% | 99.4% |
"Stacked" = delta encoding + session dedup composed (see Delta Encoding).
Cross-tokenizer consistency
Savings are stable across all major tokenizer families:
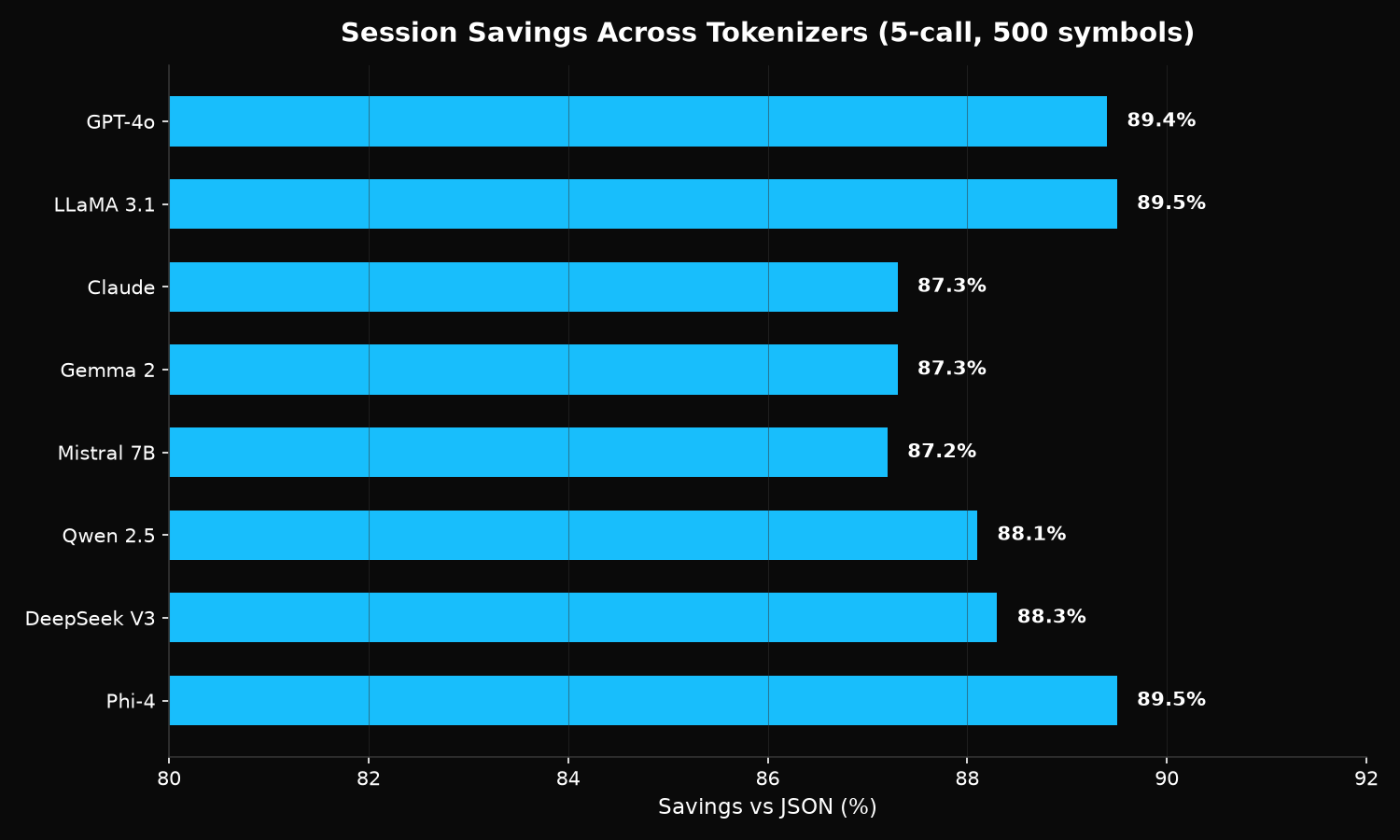
| Tokenizer | Stacked savings vs JSON |
|---|---|
| GPT-4o (OpenAI) | 89.4% |
| Claude (Anthropic) | 87.3% |
| LLaMA 3.1 (Meta) | 89.5% |
| Gemma 2 (Google) | 87.3% |
| Mistral 7B | 87.2% |
| Qwen 2.5 (Alibaba) | 88.1% |
| DeepSeek V3 | 88.3% |
| Phi-4 (Microsoft) | 89.5% |
| Average | 88.3% |
Range: 87.2% to 89.5% (2.3pp spread). The savings are a structural property of the format, not an artifact of any specific tokenizer.
The savings compound because code graphs have high locality: related queries tend to traverse overlapping neighborhoods.