Tokenizer Analysis
Every LLM uses a different tokenizer. A format designed for one tokenizer might perform poorly on another. This page proves GCF's token savings and structural consistency hold across all major tokenizers, and explains why JSON breaks down at the tokenization level.
Key Numbers (43 tokenizers, 20 providers)
- GCF vs JSON savings: 49-72%, mean 56% (every tokenizer, every scale)
- GCF vs TOON savings: 18-43%, mean 28% (every tokenizer, every scale)
- GCF boundary merge rate: 0.47% (pipe never merges with field names)
- JSON boundary merge rate: 8.17% (quote fuses with field names on 30% of tokenizers)
- TOON boundary merge rate: 32.91% (tab merges on 100% of GPT-4o tokens tested)
- GCF grammar isolation: 99.5% (@ and < are 100%, | is 99.2%)
- JSON grammar fusion: 92.5% of quote tokens are multi-grammar fusions on 43/43 tokenizers
The Core Question
When you send structured data to an LLM, the tokenizer converts it into a sequence of integer IDs. Different models use different tokenizers, each trained on a different corpus (the large text dataset used to learn which byte sequences to merge into tokens). These corpora include code repositories, web pages, books, and other text sources. Different corpora produce different vocabularies, which means different tokenizers. This raises two questions:
- Are GCF's token savings consistent? If GCF saves 58% on GPT-4 but only 20% on Claude, the savings claims are misleading.
- Are GCF's structural boundaries consistent? If different models see the data's field boundaries at different token positions, comprehension will vary per model.
The answer to both: yes, GCF is consistent. JSON is not.
First, an important distinction. A format has two types of content:
- Grammar symbols (delimiters, structural markers): These define where fields start and end. A format designer controls these.
- Payload content (the actual data values): These are the user's data.
userName,req_xyz789,Alice Chen. A format designer cannot control how these tokenize without changing the data itself, which is unacceptable.
This leads to two types of equivalence across tokenizers:
- Structural equivalence: all models see field boundaries at the same token positions. They agree on WHERE the structure is.
- Semantic equivalence: all models see the same data values. They agree on WHAT the content is.
Semantic equivalence is always preserved regardless of format: whether userName is 1 token or 2, the model reads the same characters. Tokenizer differences in payload content don't affect meaning.
Structural equivalence is the critical one. If models disagree on where fields start and end, they're parsing different structures from the same input. This is what causes model-dependent comprehension failures.
GCF guarantees structural equivalence. The pipe is always its own token, so every model sees field boundaries at the same position, regardless of how values split.
JSON does not. Its grammar symbols (quotes, colons) merge with payload content on a third of tokenizers, making field boundaries invisible at the token level. The structure and the data become one token. Models disagree on where fields start.
Tokenizers Tested
43 tokenizers from 20 providers, covering every major LLM family in production. This is the most comprehensive tokenizer boundary analysis published for any wire format.
| Provider | Tokenizers | Models Covered |
|---|---|---|
| OpenAI | cl100k_base, o200k_base, GPT-2 | GPT-4, GPT-4o, GPT-5.x |
| Anthropic | Claude tokenizer | Claude 3.5, 4.x |
| Meta | LLaMA 2, LLaMA 3, LLaMA 3.1, CodeLlama, TinyLlama | LLaMA family |
| Gemma 2, Gemma 3, T5 | Gemma family | |
| Mistral | 7B v0.1, 7B v0.3, Nemo, Mixtral, Codestral | Mistral/Mixtral family |
| Alibaba | Qwen 2, Qwen 2.5, Qwen 2.5 Coder, Qwen 3, QwQ | Qwen family |
| DeepSeek | V2 Lite, V3, R1, Coder V2 Lite | DeepSeek family |
| Microsoft | Phi-2, Phi-3, Phi-4 | Phi family |
| TII | Falcon 7B, 40B, 2 11B | Falcon family |
| 01.AI | Yi 1.5, Yi Coder | Yi family |
| BigCode | StarCoder2 7B, 15B | StarCoder family |
| NVIDIA | Nemotron Mini 4B | Nemotron |
| AI21 | Jamba v0.1 | Jamba |
| Stability AI | StableLM 2 1.6B | StableLM |
| EleutherAI | Pythia 6.9B | Pythia/GPT-NeoX |
| Snowflake | Arctic | Arctic |
| AllenAI | OLMo 7B | OLMo |
| Alibaba (AIDC) | Marco-o1 | Marco |
These tokenizers were trained on different corpora with different merge priorities. Their disagreements on how to tokenize the same input reveal fundamental properties of that input's structure. Vocabulary sizes range from 32K (Mistral 7B, LLaMA 2, Arctic) to 262K (Gemma 3).
Part 1: GCF Savings Are Consistent
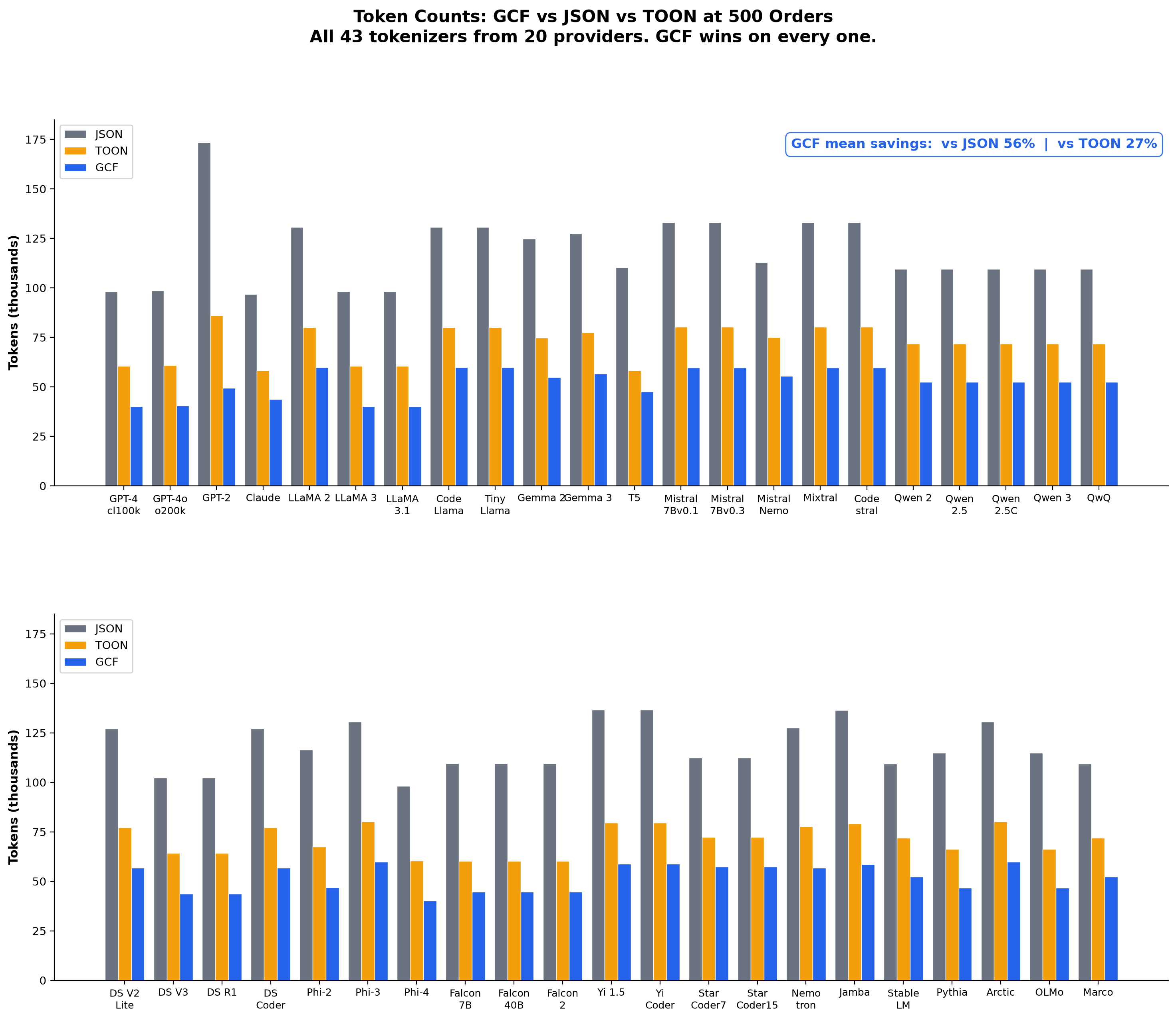
Data from eval/hf-tokenizer-analysis.py (43 tokenizers, 20 providers).
49-72% savings on every tokenizer
Representative results at 500 orders (all 43 tokenizers tested):
| Tokenizer | GCF Tokens | JSON Tokens | Savings |
|---|---|---|---|
| GPT-4 (OpenAI cl100k) | 40,190 | 98,148 | 59.1% |
| GPT-4o (OpenAI o200k) | 40,591 | 98,548 | 58.8% |
| Claude (Anthropic) | 43,704 | 96,719 | 54.8% |
| LLaMA 3.1 (Meta) | 40,190 | 98,148 | 59.1% |
| Qwen 2.5 (Alibaba) | 52,402 | 109,468 | 52.1% |
| DeepSeek V3 | 43,694 | 102,348 | 57.3% |
| Gemma 2 (Google) | 54,906 | 124,719 | 56.0% |
| Mistral Nemo | 55,407 | 112,968 | 51.0% |
| Phi-4 (Microsoft) | 40,190 | 98,148 | 59.1% |
| Falcon 7B (TII) | 44,649 | 109,599 | 59.3% |
| Yi Coder (01.AI) | 58,867 | 136,668 | 56.9% |
| StarCoder2 (BigCode) | 57,356 | 112,419 | 49.0% |
Every tokenizer produces 49%+ savings. The worst case (StarCoder2, 49.0%) still nearly halves the token count. This is measured on 500-order nested data (the generic profile from our comprehension eval) vs pretty-printed JSON (2-space indent), which is what LLMs typically receive from tool responses.
On the 16-dataset token efficiency benchmark, GCF vs JSON savings range from 43-65% depending on data complexity, with an overall average of 54.8%.
Stable from 10 to 500 records
| Payload | Min Savings | Max Savings | Mean Savings | Spread |
|---|---|---|---|---|
| 10 orders | 49.2% | 70.3% | 55.5% | 21.1pp |
| 50 orders | 50.1% | 71.8% | 56.7% | 21.7pp |
| 100 orders | 50.0% | 71.9% | 56.7% | 21.8pp |
| 500 orders | 49.0% | 71.5% | 55.9% | 22.5pp |
The mean savings holds at 55-57% across all 43 tokenizers at every scale.
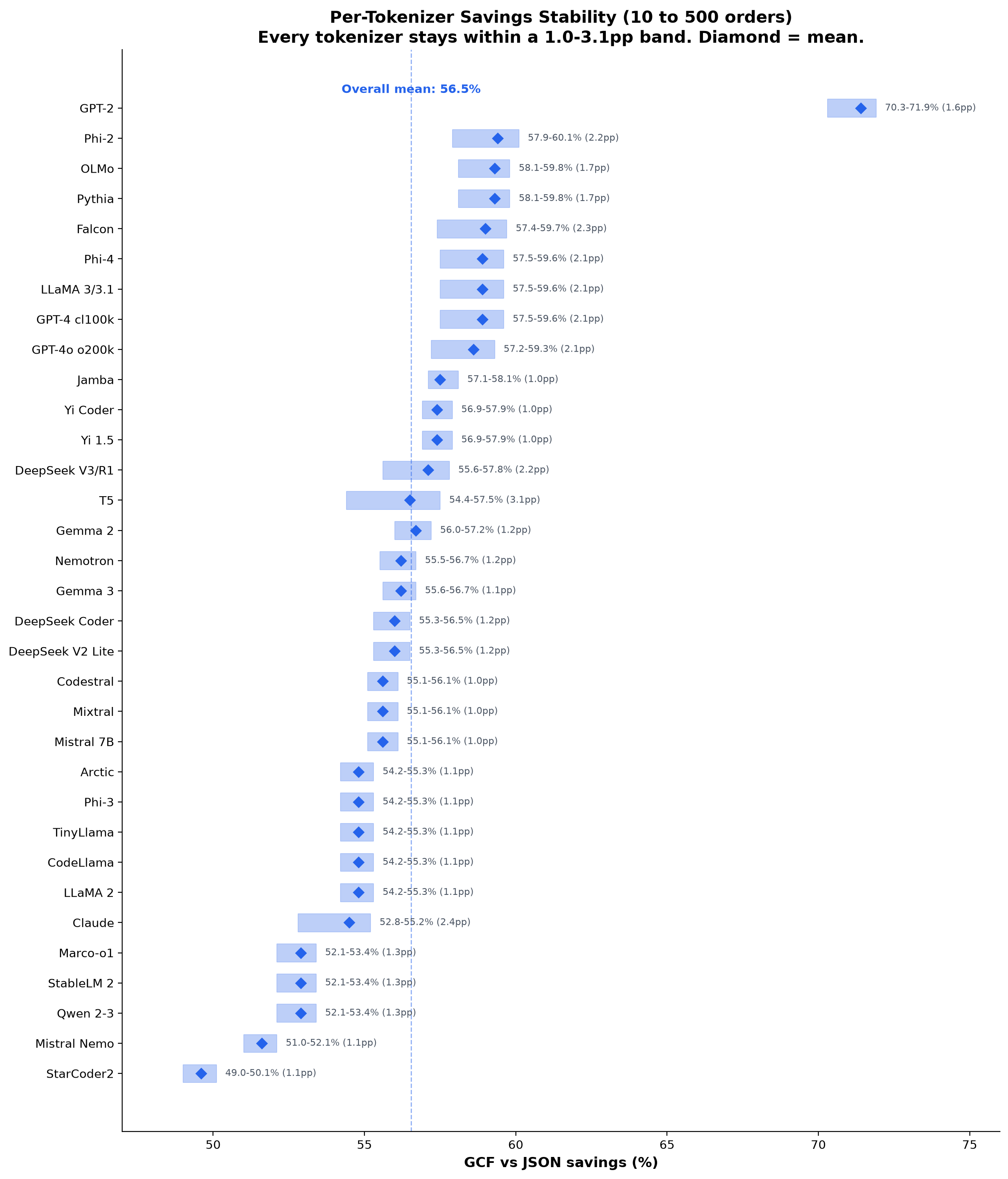
Per-tokenizer stability (10 to 500 records)
Each tokenizer's savings are remarkably stable across payload sizes. GCF beats both JSON and TOON on every tokenizer at every scale.
| Tokenizer | vs JSON (mean) | vs JSON (range) | vs TOON (mean) | vs TOON (range) |
|---|---|---|---|---|
| GPT-4 (OpenAI cl100k) | 58.9% | 2.0pp | 33.3% | 2.3pp |
| GPT-4o (OpenAI o200k) | 58.6% | 2.1pp | 32.9% | 2.3pp |
| Claude (Anthropic) | 54.5% | 2.4pp | 24.6% | 3.3pp |
| LLaMA 2 (Meta) | 54.8% | 1.1pp | 25.8% | 1.0pp |
| LLaMA 3/3.1 (Meta) | 58.9% | 2.0pp | 33.3% | 2.3pp |
| Qwen 2-3 (Alibaba) | 52.9% | 1.3pp | 27.8% | 1.3pp |
| DeepSeek V3/R1 | 57.1% | 2.1pp | 31.5% | 2.4pp |
| Gemma 2 (Google) | 56.7% | 1.2pp | 27.3% | 1.2pp |
| Gemma 3 (Google) | 56.2% | 1.1pp | 27.5% | 1.1pp |
| Mistral 7B | 55.6% | 1.1pp | 26.0% | 1.1pp |
| Mistral Nemo | 51.6% | 1.2pp | 26.6% | 1.2pp |
| Phi-2 (Microsoft) | 59.4% | 2.2pp | 30.1% | 3.0pp |
| Phi-4 (Microsoft) | 58.9% | 2.0pp | 33.3% | 2.3pp |
| Falcon (TII) | 59.0% | 2.3pp | 25.1% | 3.2pp |
| Yi Coder (01.AI) | 57.4% | 1.0pp | 26.4% | 1.4pp |
| StarCoder2 (BigCode) | 49.6% | 1.1pp | 21.0% | 1.2pp |
| Nemotron (NVIDIA) | 56.2% | 1.1pp | 27.6% | 1.1pp |
| Jamba (AI21) | 57.5% | 1.0pp | 26.3% | 1.4pp |
| StableLM 2 | 52.9% | 1.3pp | 27.8% | 1.3pp |
| Pythia (EleutherAI) | 59.3% | 1.7pp | 29.5% | 2.2pp |
| OLMo (AllenAI) | 59.3% | 1.7pp | 29.5% | 2.2pp |
| Arctic (Snowflake) | 54.8% | 1.1pp | 25.8% | 1.0pp |
Every tokenizer stays within a 1.0-3.1pp band vs JSON and 1.0-4.3pp vs TOON from 10 to 500 records. Savings are a structural property of the encoding (header factorization, positional values), not a tokenizer artifact.
Scale summary (all 43 tokenizers)
| Rows | vs JSON min | vs JSON max | vs JSON mean | vs TOON min | vs TOON max | vs TOON mean |
|---|---|---|---|---|---|---|
| 10 | 49.2% | 70.3% | 55.5% | 14.5% | 41.0% | 26.7% |
| 50 | 50.1% | 71.8% | 56.7% | 18.3% | 43.1% | 28.3% |
| 100 | 50.0% | 71.9% | 56.7% | 18.8% | 43.0% | 28.2% |
| 500 | 49.0% | 71.5% | 55.9% | 18.1% | 42.6% | 27.5% |
GCF saves 49-72% vs JSON and 18-43% vs TOON across every tokenizer at every scale. The mean holds steady: ~56% vs JSON, ~28% vs TOON.
Why this matters
Token savings translate directly to cost savings. If your tool produces 500-record responses:
- On GPT-4o: you save 58,000 tokens vs JSON (58.8%) and 20,200 vs TOON (32.9%)
- On Claude: you save 53,000 tokens vs JSON (54.8%) and 14,600 vs TOON (24.6%)
- On Gemma 2: you save 69,800 tokens vs JSON (56.0%) and 20,000 vs TOON (27.3%)
These savings are predictable regardless of which model processes the data.
The full savings picture
The ranges above are for one data type (generic profile) proving cross-tokenizer consistency. The actual savings depend on data complexity and usage pattern:
| Scenario | GCF vs JSON | GCF vs TOON | What drives it |
|---|---|---|---|
| Generic profile (500 orders, 43 tokenizers) | 49-72% | 18-43% | Header factorization, inline schemas |
| 16-dataset benchmark (mixed real payloads) | 43-65% | 15/16 wins, 29% overall | Data complexity determines savings |
| Graph profile (500 symbols + 200 edges) | 63-69% | n/a (TOON can't encode graphs) | @id refs, edge encoding, section headers |
| Session dedup (90% overlap, call 3 of 5) | 89-90% | n/a | Bare references for previously-seen symbols |
| Session dedup (full 5-call session total) | 84.3% | n/a | Format + dedup combined |
The graph profile and session deduplication benchmarks show that GCF's advanced features (compact edge encoding, bare references) push savings well beyond the baseline. In a real agent session with repeated tool calls to the same codebase, cumulative savings reach 84-92%.
All numbers cross-tokenizer validated across 43 tokenizers from 20 providers.
Part 2: Why JSON Breaks Down
Data from eval/hf-tokenizer-analysis.py (43 tokenizers, 20 providers).
The structural boundary problem
JSON uses quote-colon patterns ("fieldName":) to mark each field. These patterns repeat on every row. We discovered that these patterns tokenize inconsistently across models: the opening quote sometimes merges with the field name into a single token.
When GPT-4 tokenizes "value":"pending", it produces:
["value] [":"] [pending] ["] (4 tokens)The opening quote and field name value are one token. Claude tokenizes the same string as:
["] [value] [":"] [pending] ["] (5 tokens)The quote is separate from the field name. The structural boundary (where the field name starts) is at a different token position depending on which model processes the data.
This is verified across all 43 tokenizers:
- Merged (4 tokens): GPT-4, GPT-4o, LLaMA 3/3.1, Qwen (all versions), Phi-4, StableLM 2, Marco-o1
- Partially merged (some fields): Mistral Nemo (4 of 45 fields)
- Separate (5 tokens): Claude, Gemma 2/3, DeepSeek (all versions), Falcon, Yi, StarCoder2, Phi-2/3, and 16 others
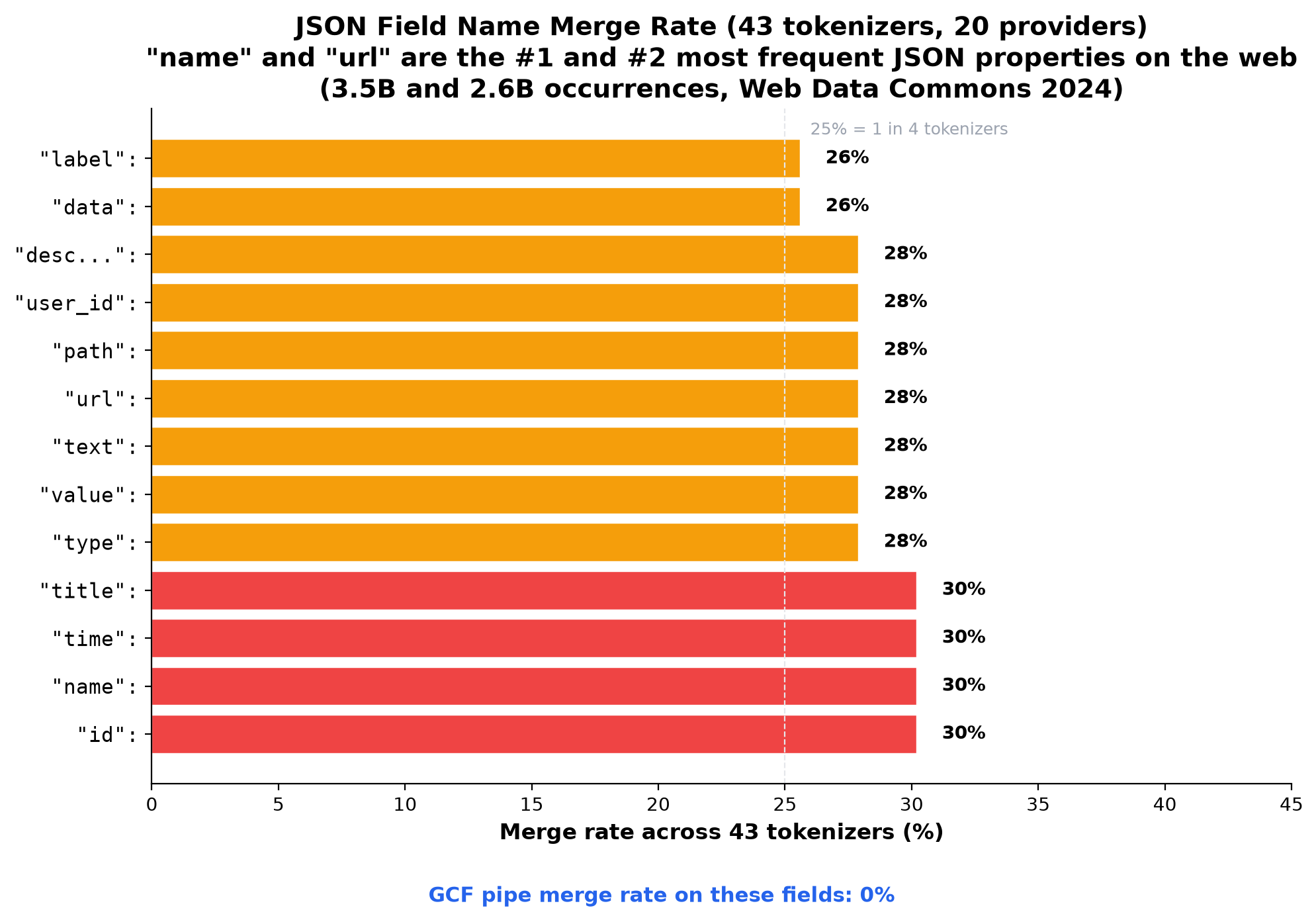
Common business field analysis (45 fields, 43 tokenizers)
We tested 45 common field names from production APIs across all 43 tokenizers (eval/hf-tokenizer-analysis.py). The most common field names in computing merge on roughly 30% of all tokenizers:
| Field | Merge rate | Tokenizer families affected |
|---|---|---|
"id": | 30.2% (13/43) | GPT-4, GPT-4o, LLaMA 3.x, Qwen, Phi-4, StableLM, Marco, Mistral Nemo |
"name": | 30.2% (13/43) | Same group |
"time": | 30.2% (13/43) | Same group |
"title": | 30.2% (13/43) | Same group |
"type": | 27.9% (12/43) | Same group minus Mistral Nemo |
"value": | 27.9% (12/43) | Same group minus Mistral Nemo |
"url": | 27.9% (12/43) | Same group minus Mistral Nemo |
"text": | 27.9% (12/43) | Same group minus Mistral Nemo |
"path": | 27.9% (12/43) | Same group minus Mistral Nemo |
"user_id": | 27.9% (12/43) | Same group minus Mistral Nemo |
"description": | 27.9% (12/43) | Same group minus Mistral Nemo |
These are not obscure fields. According to the Web Data Commons dataset (University of Mannheim, 2024), name is the #1 most common JSON property on the web (3.5 billion occurrences across 2.39 billion pages) and url is #2 (2.6 billion occurrences). Both merge on 28-30% of tokenizers.
At 500 rows with just id + name + type, that's 1,500 field boundaries where nearly a third of all models see a hidden merge.
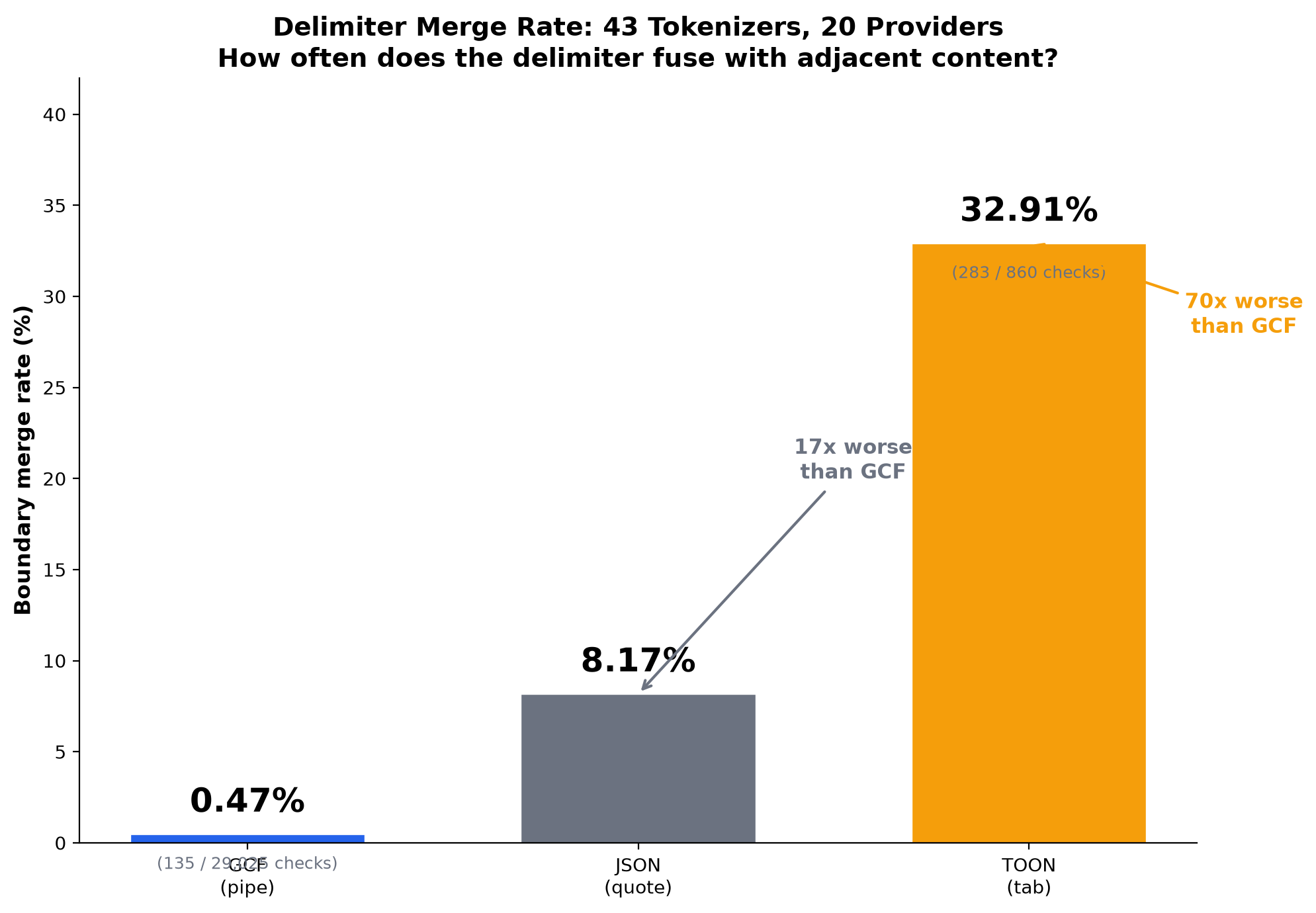
TOON's tab delimiter is worse
TOON, the primary competing token-efficient format, uses tab characters as column delimiters. The same analysis across 43 tokenizers shows TOON's tab merges far more aggressively than JSON's quote:
| Format | Delimiter merge rate | Checks |
|---|---|---|
| TOON (tab) | 32.91% | 283/860 |
| JSON (quote) | 8.17% | 158/1,935 |
| GCF (pipe) | 0.47% | 135/29,025 |
GPT-4o has a 100% tab merge rate: every single word tested merges with the preceding tab. GPT-4 cl100k merges 95%. These are the two most widely deployed tokenizers in the world. See GCF vs TOON for the full comparison.
Why merging matters for comprehension
When a model sees ["value] as one token, it must learn to decompose this into "opening quote + field name." This is an extra inference step that doesn't exist when the boundary is explicit.
At 10 records, this barely matters. Models handle it fine. But at 500 records, there are thousands of these merged boundaries competing for attention. The model's attention mechanism must repeatedly decode structural position from ambiguous tokens across 10,000+ positions.
This is why our comprehension eval shows:
- 100% accuracy at small scale (all formats)
- 53.4% JSON accuracy at 500 records (stress scale)
- 91.2% GCF accuracy at 500 records
The degradation is caused by the combination of ambiguous boundaries AND token repetition (more on this below).
Worst case: 7 distinct tokenizations
We searched 840 JSON field+value patterns (40 field names x 21 values) to find maximum variance. The worst:
"userName":"req_xyz789" produces 7 distinct tokenizations across tokenizers:
GPT-4, LLaMA: ["][userName][":"][req][_xyz][789]["]
GPT-4o: ["user][Name][":"][req][_xyz][789]["]
Claude: ["][userName][":"][req][_][xyz][789]["]
Qwen 2.5: ["][userName][":"][req][_xyz][7][8][9]["]
DeepSeek V3: ["][user][Name][":"][req][_][xyz][789]["]
Gemma 2: ["][userName][":"][req][_][xyz][7][8][9]["]
Mistral Nemo: ["][user][Name][":"][req][_x][yz][7][8][9]["]Almost every model sees a structurally different token sequence. Note how GPT-4o merges the quote into ["user] while others keep it separate.
A complete JSON object {"orderId":"ORD-001","value":"shipped"} produces 4 different token counts (12, 13, 14, 15) depending on the model. The same data is literally a different length on different model families.
Part 3: GCF Grammar Merges 94% Less
Data from eval/hf-tokenizer-analysis.py (43 tokenizers).
Boundary merge rates across 43 tokenizers
| Format | Boundary merges | Rate | Cause |
|---|---|---|---|
| GCF | 135/29,025 | 0.47% | Only |cancelled on 3 tokenizers (Mistral Nemo, DeepSeek V3, DeepSeek R1) |
| JSON | 158/1,935 | 8.17% | "id":, "name":, "type": etc. merge on 13/43 tokenizers |
| TOON | 283/860 | 32.91% | Tab merges on GPT-4o (100%), GPT-4 (95%), LLaMA 3 (95%), Qwen (95%) |
GCF has 94.3% fewer boundary merges than JSON on real data.
The critical difference: JSON's merges are caused by field names (which repeat on every row, compounding at scale). GCF's merges are caused by one specific value (cancelled) on 3 tokenizers. At 500 rows with "id" and "name" fields, JSON has ~500 hidden boundaries. GCF has zero on field names.
GCF's grammar characters are always 1 token in isolation on all 43 tokenizers:
| Character | Purpose | Single token (43/43) |
|---|---|---|
| (pipe) | Field delimiter | Yes |
@ | Symbol ID prefix | Yes |
< | Edge direction | Yes |
## | Section header | Yes |
\n | Row separator | Yes |
{ } [ ] , | Schema/count | Yes |
With typical adjacent content (alphabetic values, numbers), pipe remains separate:
value|pending -> [value][|][pending] ALL 43 tokenizers
name|Alice -> [name][|][Alice] ALL 43 tokenizers
orderId|ORD-001 -> [orderId][|][ORD][-][001] ALL 43 tokenizersUnder adversarial conditions (the specific value cancelled), pipe can merge on 3 tokenizers (Mistral Nemo, DeepSeek V3/R1) due to a |c vocabulary entry. However, even when this occurs, the pipe is always at the start of the merged token ([|c]), meaning the boundary position is still identifiable. In JSON, the quote merges with the field name after it (["value]), hiding the boundary inside.
On real data across 43 tokenizers: GCF 0.47% vs JSON 8.17%. Pipe never merges with any of the 45 field names tested.
The same data in both formats
Using the verified example "value":"pending" vs value|pending:
JSON (variance):
- GPT-4, GPT-4o, LLaMA 3.x, Qwen, Phi-4, StableLM, Marco:
["value][":"][pending]["](4 tokens) - Claude, DeepSeek, Gemma, Falcon, Yi, StarCoder, and 16 others:
["][value][":"][pending]["](5 tokens)
GCF (no variance):
- All 43 tokenizers:
[value][|][pending](3 tokens)
Same data. JSON produces two different structural representations. GCF produces one.
Why this was a deliberate design choice
Before choosing GCF's grammar, we tested all 94 printable ASCII characters (codes 33-126) across tokenizers on two criteria:
- Single token in isolation: does the character encode as exactly 1 token?
- Never merges with adjacent text: does
Xfootokenize asX+foo(separate) orXfoo(merged)?
74 of 94 characters are safe. 20 characters merge. The unsafe characters include:
| Character | Why it merges |
|---|---|
. | Merges into .validate, .com, .json |
- | Merges into -token, -based, -style |
_ | Merges into _name, _id, _count |
/ | Merges into /api, /path |
( | Merges into (foo on some tokenizers |
| Lowercase letters | Common subword prefixes |
JSON uses ., ", and : as structural characters. All three can create merge patterns. GCF uses only characters from the safe set (|, @, <, #, {, }, [, ], ,, \n).
Part 4: JSON's Token Overhead Problem
Data from eval/json-tokenization-analysis.mjs.
Beyond structural ambiguity, JSON also burns the majority of its tokens on content that carries zero information after the first row.
Where tokens go (500-row frequency table)
| Category | JSON tokens | % of total |
|---|---|---|
Repeated field names ("field":, "value":, etc.) | 5,500 | 52.4% |
Structural characters ({, }, [, ], :, ,) | 3,001 | 28.6% |
| Actual data values | 1,995 | 19.0% |
| Total | 10,496 |
81% of JSON's tokens are overhead. Only 19% carry actual information.
GCF for the same data:
| Category | GCF tokens | % of total |
|---|---|---|
| Header (field names, declared once) | 10 | 0.2% |
| Data rows | 6,500 | 99.8% |
| Total | 6,510 |
The cost per field
Each JSON field-name pattern costs tokens on every single row:
| Field pattern | Tokens per row | x 500 rows | Total cost |
|---|---|---|---|
"field": | 3 | x 500 | 1,500 tokens |
"value": | 2 | x 500 | 1,000 tokens |
"count": | 3 | x 500 | 1,500 tokens |
"percentage": | 3 | x 500 | 1,500 tokens |
In GCF, all four field names appear once in the header:
## [500]{field,value,count,percentage}Cost: 10 tokens total. Same information, 550x fewer tokens.
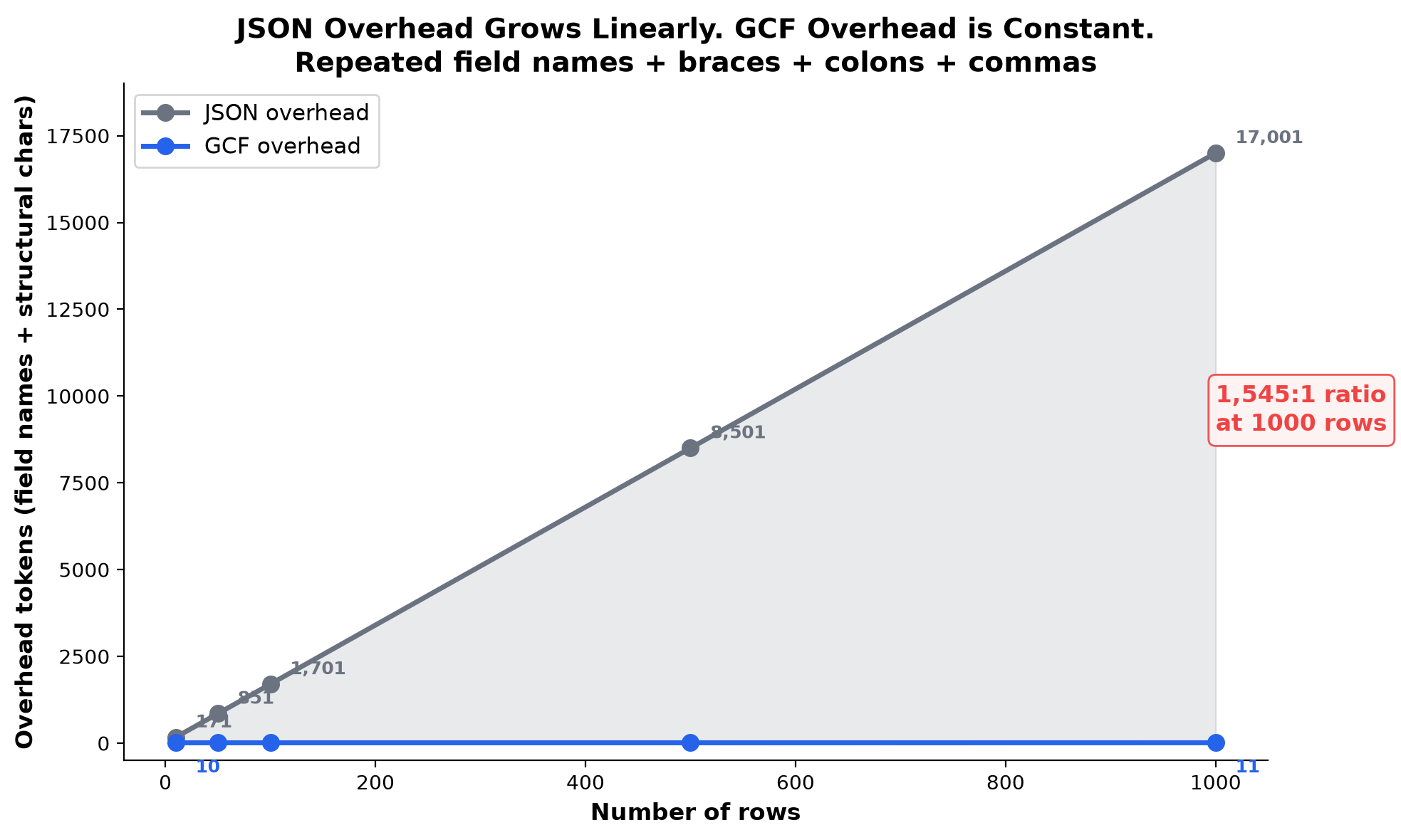
JSON overhead grows linearly. GCF is constant.
| Rows | JSON overhead | GCF overhead | Ratio |
|---|---|---|---|
| 10 | 171 tokens | 10 tokens | 17:1 |
| 50 | 851 tokens | 10 tokens | 85:1 |
| 100 | 1,701 tokens | 10 tokens | 170:1 |
| 500 | 8,501 tokens | 10 tokens | 850:1 |
| 1,000 | 17,001 tokens | 11 tokens | 1,545:1 |
At 1,000 rows, JSON burns 17,001 tokens on overhead. GCF uses 11. Every additional row adds ~17 tokens of overhead in JSON and zero in GCF.
Cross-tokenizer validation
Representative cross-tokenizer validation (500-row frequency table):
| Tokenizer | JSON tokens | GCF tokens | Savings | JSON field-name overhead |
|---|---|---|---|---|
| Claude (Anthropic) | 10,996 | 7,013 | 36.2% | 54.6% |
| GPT-4 (OpenAI cl100k) | 10,494 | 6,508 | 38.0% | 52.4% |
| GPT-4o (OpenAI o200k) | 10,494 | 6,508 | 38.0% | 52.4% |
| LLaMA 3.1 (Meta) | 10,494 | 6,508 | 38.0% | 52.4% |
| Qwen 2.5 (Alibaba) | 13,150 | 9,166 | 30.3% | 41.8% |
| DeepSeek V3 | 10,494 | 6,509 | 38.0% | 57.2% |
| Gemma 2 (Google) | 14,149 | 9,669 | 31.7% | 42.4% |
| Mistral Nemo | 13,649 | 9,167 | 32.8% | 44.0% |
Every tokenizer confirms: JSON spends 42-57% of its tokens on repeated field names alone. GCF eliminates this overhead entirely.
Part 5: Why This Explains Comprehension Failures
Connects tokenization findings to comprehension eval data (2,400+ LLM calls across 11 models).
The tokenization analysis connects directly to the comprehension eval data:
- JSON accuracy on stress-scale data: 53.4% (10 models, 24 runs, 3 providers)
- GCF accuracy on stress-scale data: 91.2% (same runs, same models)
- GCF accuracy on standard workloads: 100% on every frontier model
Why does JSON fail at scale?
- Ambiguous structural boundaries (8.17% merge rate across 43 tokenizers). The model sees different structure depending on which model reads it.
- Overwhelming repetition (52% of tokens are repeated field names). The attention mechanism has 5,500 tokens that all look identical competing for attention budget.
- Low signal-to-noise ratio (19% data, 81% overhead). The model must find relevant information buried in structural noise.
Why does GCF succeed?
- Near-zero boundary merging (0.47% merge rate). Every model sees consistent structure.
- Zero repetition (field names declared once). No identical tokens competing for attention.
- 99.8% signal (almost every token is data). The attention mechanism focuses on content.
The model doesn't fail because JSON is "too long." It fails because these three problems compound at scale:
At 10 rows: a handful of merged boundaries, small attention budget, manageable. The model has seen enough JSON to work around it.
At 500 rows: ~1,500 merged boundaries ("name:, "id":, "type": on every row), all producing the same token IDs (e.g., #32586 repeated 500 times). The model can't distinguish the 150th "name from the 350th; it relies on positional encoding alone, which degrades over long sequences. Meanwhile, 81% of the sequence is noise that the attention mechanism must scan through. The merged boundaries make the noise harder to skip because the model can't cleanly identify where structure ends and data begins.
This is why JSON errors at scale are off by 50-140 (the model couldn't find the answer at all), not off by 1-2 (slightly misread a number). GCF at 500 rows has zero merged boundaries on field names, 99.8% signal, and structure that answers questions directly (## related [167]). Nothing compounds because there's nothing to compound.
Observed failure patterns from 2,400+ evaluations
Across 24 stress-scale runs (500 symbols, 200 edges, 13 questions per run), we classified every wrong answer by failure type. The patterns connect directly to the tokenization findings:
| Model | Format | Failure pattern | Tokenization explanation |
|---|---|---|---|
| GPT-5.4 | JSON | Always answers edge_count=198 (correct: 200). Same wrong number every run. | Consistent with cl100k/o200k merge patterns: "id":, "name":, "type": merge on every row. |
| GPT-5.4 | JSON | Always answers function_count=84 (correct: varies). Deterministic. | Same mechanism. Column scan across 500 merged-boundary rows produces repeatable miscount. |
| GPT-5.5 | JSON | Returns empty string on most questions. | 53K tokens, 81% overhead. Attention has nothing to lock onto. Context overwhelm. |
| All models | JSON | Distance-filtering wrong by 50-140 (e.g., 143 vs 167). | Must attend to 500 identical "distance": patterns and filter by value. No structural marker distinguishes the 150th from the 350th. |
| Opus | JSON | Manually enumerates 143 lines trying to count, still wrong. | Model falls back to chain-of-thought enumeration because it can't structurally extract the answer. |
| Claude | GCF | Never fails. | Claude's tokenizer keeps all boundaries clean. GCF's structure answers questions directly (## related [167]). |
| GPT-5.4 | GCF | Off-by-1-2 on edge_count, function_count. Deterministic. | Pipe is always separate (structure parseable), but value content (fn vs function) may split differently. Precision error, not comprehension error. |
| All frontier | GCF | 100% on standard workloads. | 0.47% merge rate + 99.8% signal + structural answers = no failure mechanism. |
GCF's errors are small (off by 1-2) because the model understood the structure but slightly misread a value. JSON's errors are large (off by 50-140) because the model couldn't find the structure at all. Hidden boundaries compound into comprehension failure. Clean boundaries enable structural extraction.
Error magnitude:
- GCF median error: 4 (precision)
- TOON median error: 53 (comprehension failure)
- JSON median error: 56 (comprehension failure)
For the complete per-run failure data, see Benchmarks (Full Data): Failure Taxonomy.
Part 6: The Grammar Swap Experiment
Data from eval/grammar-swap-experiment.mjs.
To prove GCF's savings are structural (positional fields, keys declared once) and not an artifact of specific delimiter choices, we swapped the entire grammar and re-measured.
Method
5 delimiter sets, all using characters from the "perfect" (non-merging) category:
| Set | Field | ID | Edge | Section | Schema |
|---|---|---|---|---|---|
| GCF (actual) | | | @ | < | ## | {,} |
| Alt A | ~ | $ | > | %% | (;) |
| Alt B | ^ | ! | = | && | {:} |
| Alt C | ` | # | ~ | !! | [|] |
| Alt D | ; | % | ^ | $$ | {+} |
5 payload types, 4 sizes, 8 representative tokenizers. 800 total measurements.
Results
| Delimiter set | Overall savings |
|---|---|
| GCF (actual) | 60.6% |
| Alt set A | 60.3% |
| Alt set B | 60.7% |
| Alt set C | 60.3% |
| Alt set D | 60.4% |
Spread: 0.4 percentage points. You could replace every delimiter in the grammar and get the same compression. The format's efficiency is a mathematical property of eliminating key repetition, not an artifact of which specific characters are used.
Per-tokenizer consistency
| Tokenizer | GCF | Alt A | Alt B | Alt C | Alt D |
|---|---|---|---|---|---|
| Claude | 60.8% | 60.4% | 60.8% | 60.4% | 60.4% |
| GPT-4 | 63.2% | 62.8% | 63.2% | 62.8% | 62.8% |
| GPT-4o | 63.1% | 63.1% | 63.5% | 63.1% | 63.1% |
| LLaMA 3.1 | 63.2% | 62.8% | 63.2% | 62.8% | 62.8% |
| Qwen 2.5 | 56.3% | 55.9% | 56.3% | 55.9% | 55.9% |
| DeepSeek V3 | 63.4% | 62.9% | 62.9% | 62.9% | 63.7% |
| Gemma 2 | 60.2% | 59.9% | 60.2% | 59.9% | 59.9% |
| Mistral Nemo | 56.0% | 56.0% | 56.5% | 56.0% | 56.0% |
0.0-0.8pp variation per tokenizer across delimiter sets.
What this proves
GCF's delimiters were chosen from the safe character set as a robustness guarantee (consistent boundaries across all models). But the savings themselves come from the encoding structure:
- Field names declared once in a header (not repeated per row)
- Values encoded positionally (no key-value pair overhead)
- One line per record (no braces, no brackets per row)
Any format that makes these three structural choices would achieve similar savings, regardless of which specific delimiter characters it uses.
Part 7: Syntactic Deep Dive
For completeness, here is exactly how each tokenizer handles GCF's core syntax elements. This data is produced by eval/tokenizer-variance.mjs.
Edge declaration: @0<@2|implements
| Tokenizer | Tokens | Split |
|---|---|---|
| Claude | 7 | @ 0 < @ 2 | implements |
| GPT-4 | 7 | @ 0 < @ 2 | implements |
| GPT-4o | 7 | @ 0 < @ 2 | implements |
| LLaMA 3.1 | 7 | @ 0 < @ 2 | implements |
| Qwen 2.5 | 7 | @ 0 < @ 2 | implements |
| DeepSeek V3 | 8 | @ 0 < @ 2 | im plements |
| Gemma 2 | 7 | @ 0 < @ 2 | implements |
| Mistral Nemo | 8 | @ 0 < @ 2 | im plements |
All structural characters (@, <, |) are always single tokens. The only variance is in the value implements (1 vs 2 tokens), which doesn't affect parsing.
Symbol row: @0|function|auth.validateToken|0.95|definition
| Tokenizer | Tokens | Key Differences |
|---|---|---|
| GPT-4 | 14 | Merges .validate (1 tok), 95 (1 tok) |
| Qwen 2.5 | 15 | Splits 95 into 9 + 5 |
| Gemma 2 | 16 | Splits . + validate, splits 9 + 5 |
The pipe delimiters are always single tokens. Variance is only in how tokenizers handle value content:
- Dot-prefixed words:
.validate(1 tok on GPT-4) vs.+validate(2 tok on Gemma) - Two-digit numbers:
95(1 tok on GPT-4) vs9+5(2 tok on Qwen/Gemma)
This is value variance (harmless, doesn't affect structure) not boundary variance (dangerous, affects parsing).
Design rationale: why these specific delimiters
From the 74 perfect candidates, GCF chose based on semantics and readability:
| Character | Why chosen | Alternative considered | Why not |
|---|---|---|---|
| (pipe) | Rare in natural text. Visually distinct column separator. | Tab (\t) | Invisible, merges on 33% of tokenizers |
@ | Establishes "this is an ID" semantically. | $ | Also perfect, but less intuitive |
## | Two-char sequence that tokenizers always merge into one token. Markdown-familiar. | === | 3 chars, less efficient |
< | Reads as "points to" for edges. | ~ | Also perfect, but less semantic |
\n | Universal row separator. Zero overhead. | ; | Less readable |
, | Schema field separator. Familiar from CSV. | : | Conflicts with potential value content |
Part 8: Root Cause: Vocabulary Entry Analysis
Data from eval/hf-tokenizer-analysis.py (43 tokenizers).
Parts 2-3 showed that JSON's grammar merges with payload content. Part 4 showed the overhead. Part 5 connected it to comprehension failures. But none of those answered the fundamental question: why does the merge happen?
The answer is in the tokenizer vocabularies themselves.
How BPE tokenizers work
Every BPE tokenizer has a fixed vocabulary: a table mapping strings to integer IDs. GPT-4's cl100k vocabulary has ~100K entries. Gemma 3's has 262K. These are built during tokenizer training (separate from model training) by iteratively merging the most frequent byte pairs in the training corpus.
When the tokenizer encounters input text, it greedily matches the longest vocabulary entry at each position. If "name exists as entry #32586, the tokenizer will always select it as a single token rather than splitting into " (#1) + name (#609). This is deterministic. There is no probability or context-dependence. If the entry exists, it wins.
JSON field names are vocabulary entries
We scanned the complete vocabulary of all 43 tokenizers and counted entries where grammar characters are fused with payload content:
| Tokenizer | Vocab size | Quote+letter | Pipe+letter | Tab+letter | Multi-grammar |
|---|---|---|---|---|---|
| GPT-4 (cl100k) | ~100K | 117 | 22 | 1,173 | 874 |
| GPT-4o (o200k) | ~199K | 108 | 8 | 1,036 | 735 |
| Claude | ~65K | 3 | 0 | 0 | 667 |
| LLaMA 2 | ~32K | 0 | 0 | 0 | 122 |
| LLaMA 3/3.1 | ~128K | 153 | 277 | 0 | 881 |
| Qwen 2.5 | ~152K | 154 | 40 | 0 | 874 |
| DeepSeek V3/R1 | ~129K | 48 | 5 | 0 | 287 |
| Gemma 2 | ~256K | 4 | 0 | 0 | 735 |
| Gemma 3 | ~262K | 2 | 0 | 0 | 861 |
| Mistral Nemo | ~131K | 38 | 3 | 0 | 415 |
| Phi-4 | ~100K | 153 | 116 | 0 | 874 |
| Yi Coder | ~64K | 1 | 173 | 0 | 202 |
| Falcon | ~65K | 4 | 1 | 0 | 92 |
| StarCoder2 | ~49K | 3 | 2 | 0 | 535 |
| Nemotron | ~256K | 0 | 0 | 0 | 200 |
| Jamba | ~66K | 1 | 1,543 | 0 | 113 |
These are actual token IDs in the vocabulary. Entry #32586 in GPT-4's vocabulary IS the string "name. It will always be selected. This is not a context-dependent merge decision. It's a dictionary lookup.
The tab vocabulary problem
The most striking finding from the 43-tokenizer study: GPT-4 cl100k has 1,173 tab+letter vocabulary entries and GPT-4o o200k has 1,036. Tab-separated data was so common in the training corpora (TSV files, log output, terminal formatting) that the tokenizer absorbed tabs more aggressively than any other delimiter. No other tokenizer has tab+letter entries. TOON chose the single worst delimiter for the two most widely deployed tokenizers.
Cross-verification: vocabulary entries are actually used
We confirmed that every vocabulary entry is selected during real tokenization:
"name":"Alice"
GPT-4: CONFIRMED: vocab entry #32586 selected -> ["name][":"][Alice]["]
Claude: clean: not in vocab, not selected -> ["][name][":"][Alice]["]The entry isn't dead vocabulary. It actively causes boundary hiding in every JSON payload that contains a name field.
Why these entries exist
BPE builds vocabulary by counting byte-pair frequencies in the training corpus. JSON is one of the most common data formats in code training data:
- Every GitHub repository has
package.json,tsconfig.json, configuration files - Every API documentation shows JSON request/response examples
- Every Stack Overflow answer about web development demonstrates JSON parsing
- Every log file, data dump, and test fixture contains JSON
The byte sequence "name appears in training data billions of times. The tokenizer learned it as a high-frequency merge and added it to the vocabulary. This is efficient for compression (fewer tokens to represent common patterns), but it creates structural ambiguity: the grammar symbol (") and the payload content (name) become inseparable.
The training familiarity paradox
The conventional wisdom is that LLMs "know" JSON best because they've been trained on more JSON than any other structured format. This is true at the model level. But at the tokenizer level, the opposite happens: the more JSON the tokenizer saw, the more aggressively it merged JSON patterns, and the more structural boundaries it hid.
The models that saw the MOST JSON have the WORST JSON boundaries:
- GPT-4 (massive code corpus): 117 merged entries
- LLaMA 3 (large code mix): 153 merged entries
- Qwen 2.5 (heavy code training): 154 merged entries
- Claude (different tokenizer strategy): 3 merged entries
- Gemma 2/3 (different merge policy): 2-4 merged entries
The training familiarity didn't create structural understanding. It created compression. The tokenizer optimized for representing JSON in fewer tokens, which is exactly what a compression algorithm should do. But compression hides structure. The quote and the field name became one token because that's more efficient for storage. It's less efficient for comprehension.
This inverts the standard argument entirely. "Trained on JSON" is not an advantage for structural comprehension. It's the mechanism that causes structural ambiguity. The tokenizer's efficiency is the model's handicap.
Why Claude and Gemma don't have this problem
Claude's tokenizer has 3 quote+letter entries. Gemma 2 has 4. Gemma 3 has 2. Across the 43 tokenizers tested, the pattern is clear: 11 tokenizers have zero or near-zero quote merge entries.
The tokenizer training details are proprietary, but there are measurable differences that explain it:
- Vocabulary size: Claude's vocabulary is ~65K (one of the smallest tested). Smaller vocabularies are more conservative about which merges to include. But Gemma 3's vocabulary is the largest (262K) yet has only 2 quote merges. Vocabulary size alone doesn't predict merge behavior.
- Training data mix: Tokenizers trained on corpora with less code/JSON relative to natural language will see
"nameless frequently, making it less likely to cross the merge threshold. - Merge boundary policy: BPE training can be configured to treat certain characters as merge barriers (never merge across them). Anthropic and Google may have intentionally prevented
"from merging with adjacent letters.
The result is measurable regardless of cause: Claude and Gemma keep structural boundaries clean. GPT-4, GPT-4o, LLaMA 3, Qwen, and Phi-4 do not.
Why this is irrecoverable
Four properties make this unfixable:
Vocabulary is frozen. Once the tokenizer is trained, its vocabulary never changes. Model fine-tuning adjusts weights but cannot add, remove, or modify vocabulary entries.
All existing weights depend on the vocabulary. Token ID #32586 has a learned embedding vector in GPT-4's weights. If you removed it, every layer that references that embedding would break.
The merge is pre-model. Tokenization happens before the model sees the input. By the time the transformer processes the sequence,
"nameis already a single integer. The model cannot "see inside" a token to decompose it.Retraining the tokenizer requires retraining the model. A new vocabulary means new token IDs, new embeddings, new attention patterns. The entire model must be retrained from scratch.
This means: for every model using GPT-4's cl100k or GPT-4o's o200k tokenizer, the string "name will always be one token. The structural boundary will always be hidden. No amount of prompting, fine-tuning, or RLHF can change this. It's a dictionary entry.
The complete adversarial surface
Data from eval/adversarial-vocab-dump.py.
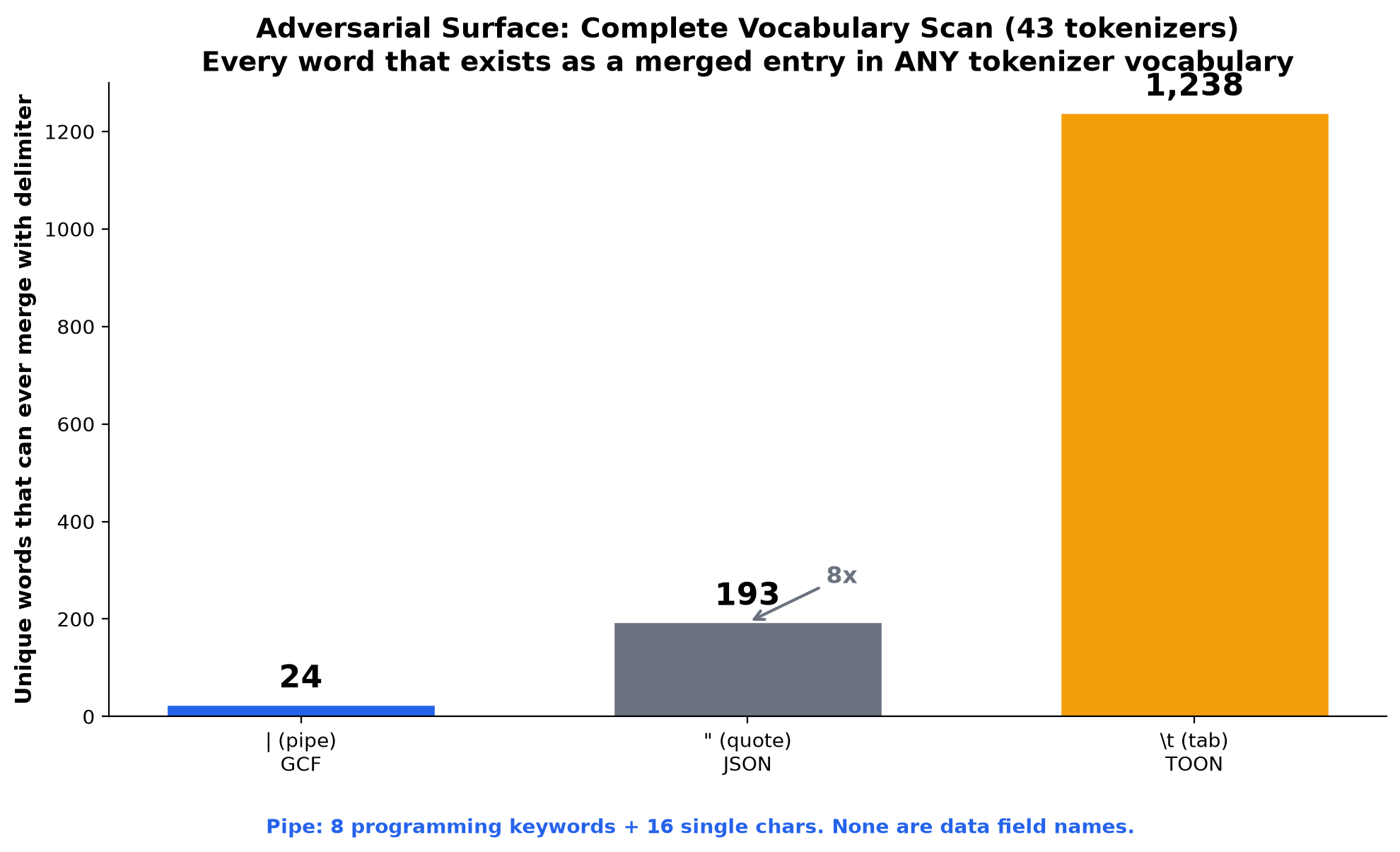
BPE is deterministic. If |foo exists as a vocabulary entry, the tokenizer WILL select it as a single token. If |foo does NOT exist in the vocabulary, | and foo MUST be separate tokens. No context, no probability, no exceptions. So the definitive answer to "what can merge with the pipe?" is: dump every vocabulary entry that starts with | from every tokenizer. That's the complete adversarial surface.
We scanned all 43 tokenizer vocabularies (32K to 262K entries each). The pipe delimiter has exactly 24 words that can ever merge across any tokenizer:
| Entry | Tokenizers | Origin |
|---|---|---|
|null | 15/43 | TypeScript union: string|null |
|x | 13/43 | Single character |
|string | 12/43 | TypeScript union: number|string |
|required | 12/43 | Schema syntax: optional|required |
|max | 12/43 | TypeScript union |
|min | 12/43 | TypeScript union |
|array | 11/43 | TypeScript type |
|int | 11/43 | TypeScript/Go union |
|unique | 11/43 | SQL/schema keyword |
|m, |r, |h, |i, |M, |R | 11/43 | Single characters |
|RF, |wx | 11/43 | Abbreviations |
|l | 5/43 | Single character |
|c | 3/43 | Single character (causes |cancelled merge) |
|get | 1/43 | HTTP method (Jamba only) |
8 are programming keywords (null, string, required, array, max, min, int, unique). The rest are single characters or abbreviations. None are data field names. None are common data values.
For comparison, the same exhaustive scan on JSON's quote and TOON's tab:
| Delimiter | Unique mergeable words | Ratio to pipe |
|---|---|---|
| (pipe) | 24 | 1x |
" (quote) | 193 | 8x |
\t (tab) | 1,238 | 52x |
The quote has 8x more mergeable words than the pipe. The tab has 52x more. TOON chose the delimiter with the largest adversarial surface of any common separator character. GCF chose the one with the smallest.
GPT-4 cl100k has 1,173 tab+letter vocabulary entries and 22 pipe+letter entries. GPT-4o o200k has 1,036 tab+letter entries and 6 pipe+letter entries. Tab-separated data was so prevalent in tokenizer training corpora (TSV files, terminal output, log formatting) that nearly every common word is fused with the tab character in these vocabularies.
|name, |id, |type, |value, |status, |title do not exist as vocabulary entries on any of the 43 tokenizers. The pipe will never merge with any common field name. This is not a statistical claim from sampling. It is a dictionary fact.
Part 9: Structural Equivalence Proof

Data from eval/structural-equivalence-proof.py (43 tokenizers).
Parts 2-8 measured merge rates, vocabulary entries, and overhead. This part asks the ultimate question: is GCF's grammar deterministic? When you tokenize a GCF payload on any production tokenizer, does every grammar symbol remain its own token?
GCF: every grammar symbol is isolated
We tokenized a realistic multi-section GCF payload (5 orders + 3 edges) across all 43 tokenizers and checked every token containing a row-level grammar symbol (|, @, <):
| Symbol | Purpose | Total tokens | Isolated | Merged | Isolation rate |
|---|---|---|---|---|---|
@ | Symbol ID prefix | 258 | 258 | 0 | 100.0% |
< | Edge direction | 126 | 126 | 0 | 100.0% |
| | Field delimiter | 774 | 768 | 6 | 99.2% |
| Overall | 1,158 | 1,152 | 6 | 99.5% |
@ and < are perfectly isolated on every tokenizer. Not a single exception across 258 + 126 = 384 tokens on 43 tokenizers.
The 6 pipe exceptions are all |c in the value cancelled on 3 tokenizers (Mistral Nemo, DeepSeek V3, DeepSeek R1). Pipe never merges with any field name on any tokenizer.
This means: when a model reads GCF, every | it encounters is a standalone token marking a field boundary. Every @ marks a symbol ID. Every < marks an edge direction. The grammar is unambiguous. The model doesn't need to learn to decompose grammar from payload; they're always in separate tokens.
JSON: grammar fuses into multi-operation tokens
We tokenized equivalent JSON data (same 5 records, using common field names id, name, type, status, value) across all 43 tokenizers:
92.5% of quote-containing tokens fuse multiple grammar operations into a single token. This happens on all 43 tokenizers:
| Token | Grammar operations fused | Present on |
|---|---|---|
":" | Close string + colon + open string | 42/43 |
"," | Close string + comma + open string | 41/43 |
{" | Open object + open string | 42/43 |
": | Close string + colon | 43/43 |
," | Comma + open string | 41/43 |
When GPT-4 reads {"name":"Alice","type":"admin"}, it receives:
[{"] [name] [":"] [Alice] [","] [type] [":"] [admin] ["}]The token ":" represents three structural operations (end the key string, insert the key-value separator, start the value string) packed into a single integer. The token "," represents three operations (end the value string, insert the field separator, start the next key string). The model must learn that token ":" means "this is where the key ends and the value begins" as an emergent property of training, not as an explicit structural signal.
The contrast
| Property | GCF | JSON |
|---|---|---|
| Grammar tokens isolated | 99.5% | 7.5% |
| Grammar fused with grammar | 0% | 92.5% (43/43 tokenizers) |
| Grammar fused with payload | 0.5% (3 tokenizers, one value) | 0% (in full-object context) |
| Grammar is deterministic | Yes | No (grammar fuses differently per tokenizer) |
GCF's 0.5% payload fusion is the |c vocabulary entry on Mistral Nemo, DeepSeek V3, and DeepSeek R1 (from the adversarial surface analysis). It triggers only when the value cancelled (or cache, csv, custom) immediately follows a pipe. Even when it does, the pipe is at the start of the fused token ([|c][ancelled]), so the boundary position is still identifiable. This affects 3 of 43 tokenizers on a handful of specific values. It does not affect any field name.
GCF's grammar is structurally equivalent across every production tokenizer. Each delimiter is its own token. The model receives an unambiguous token sequence where grammar and payload are always in separate tokens.
JSON's grammar is structurally ambiguous on every production tokenizer. Multiple grammar operations fuse into single tokens. The model must decompose multi-operation tokens to understand where keys end and values begin. This is learned behavior, not explicit structure, and it degrades at scale when thousands of these fused tokens compete for attention.
Part 10: Attention Mechanism Analysis
Data from eval/attention-analysis.py (Pythia 410M and Gemma 2B on CPU).
Parts 2-9 proved that JSON's grammar merges, that the merges are vocabulary-level, that they're irrecoverable, and that GCF's grammar is deterministic. But all of that is at the tokenizer level. This part answers the transformer-level question: what happens inside the model when it processes merged vs clean token sequences?
We loaded Pythia 410M (24 layers, 16 heads) and Gemma 2B (26 layers, 8 heads) and extracted attention weights from every layer and head while processing identical data in GCF vs JSON at increasing scale.
Attention entropy crossover
Attention entropy measures how spread out the model's attention is. High entropy means attention is distributed uniformly (the model is looking everywhere, finding nothing). Low entropy means attention is focused (the model knows where to look).
Pythia 410M:
| Orders | GCF entropy | JSON entropy | Delta |
|---|---|---|---|
| 5 | 3.03 | 2.87 | JSON lower (model knows JSON) |
| 10 | 3.32 | 3.01 | JSON still lower |
| 20 | 3.66 | 3.16 | JSON still lower |
| 50 | 3.99 | 4.50 | JSON crosses over (+13%) |
At small scale, JSON entropy is lower than GCF's. This makes sense: the model has been trained on billions of JSON examples and has learned efficient attention patterns for JSON structure. At 5-20 orders, JSON is familiar territory.
At 50 orders, the crossover. JSON entropy exceeds GCF by 13%. The model's learned JSON parsing breaks down. The repeated field names ("name":, "status":, "total": on every row) produce thousands of identical token IDs competing for attention. The model can no longer distinguish the 10th "name from the 40th using positional encoding alone. Attention diffuses uniformly.
GCF entropy rises steadily but stays lower than JSON at scale. The model doesn't need special training to parse GCF because every delimiter is its own token. There's no learned pattern to break down.
Grammar attention collapse
We classified every token as grammar (delimiters, structural markers) or payload (data values) and measured what fraction of the model's attention goes to each category.
Gemma 2B (100 orders):
| Orders | GCF grammar% | GCF payload% | JSON grammar% | JSON payload% |
|---|---|---|---|---|
| 5 | 53.8% | 46.2% | 29.8% | 67.7% |
| 10 | 52.4% | 47.6% | 29.7% | 68.0% |
| 20 | 50.8% | 49.2% | 30.4% | 67.4% |
| 50 | 48.6% | 51.4% | 8.6% | 86.3% |
| 100 | 37.4% | 62.6% | 8.6% | 86.3% |
At small scale (5-20 orders), JSON's attention splits roughly 30% grammar / 68% payload. The model attends to structural tokens (quotes, colons, braces) to understand the format, then to payload tokens to extract data. This is healthy attention behavior.
At 50 orders, JSON grammar attention collapses from 30% to 8.6%. The model stops attending to structural tokens. Payload attention jumps from 68% to 86%. The model is no longer parsing JSON's structure; it's distributing attention uniformly across content, unable to distinguish structure from data. This is the mechanism behind comprehension failure.
GCF does the opposite. Payload attention increases steadily from 46% to 63% at 100 orders. As the payload grows, the model progressively focuses more on data and less on grammar. This is because GCF's grammar is proportionally smaller (one header vs hundreds of rows) and every grammar token is unambiguous (always its own token). The model doesn't need to attend to grammar to parse structure; the structure is explicit in the token boundaries.
Token repetition scaling
The underlying cause of both phenomena is token repetition. JSON repeats the same token IDs on every row. GCF doesn't.
| Orders | GCF repeat% | JSON repeat% | Tokens |
|---|---|---|---|
| 5 | 42.4% | 74.8% | 110 / 245 |
| 10 | 62.0% | 84.9% | 211 / 490 |
| 20 | 76.6% | 91.0% | 413 / 982 |
| 50 | 83.6% | 93.6% | 1,019 / 2,048 |
| 100 | 97.9% | 97.8% | 2,048 / 2,048* |
*At 100 orders, both formats hit Gemma 2B's 2,048-token context window. The apparent convergence is a truncation artifact: both sequences are clipped to the same length, exhausting their small unique token pools (~42-45 unique tokens). At 50 orders (the last untruncated scale), the gap is 10pp: JSON has 93.6% repetition vs GCF's 83.6%.
At 50 orders, 93.6% of JSON tokens are duplicates. The model's attention mechanism must distribute weight across hundreds of identical tokens using only positional encoding to distinguish them. This is mathematically equivalent to the attention dilution problem described by Ildiz et al. (2024): self-attention weights tokens proportionally to their frequency, so repeated tokens dominate the attention budget.
Why this matters for format design
The attention analysis reveals that JSON's comprehension failures are not caused by model limitations. They're caused by the interaction between:
- Tokenizer behavior (merged boundaries create ambiguous tokens)
- Token repetition (field names repeat on every row, producing identical token IDs)
- Attention mechanics (identical tokens dilute attention, grammar attention collapses at scale)
A format that eliminates all three problems (clean boundaries, no repetition, explicit structure) would maintain comprehension at any scale. GCF eliminates all three. That's why it scores 91.2% where JSON scores 53.4% on the same data with the same models.
Summary
| Claim | Evidence |
|---|---|
| GCF saves 49-72% vs JSON on all tokenizers | 43 tokenizers, worst case 49.0% (StarCoder2), mean 55.9% |
| GCF saves 18-43% vs TOON on all tokenizers | 43 tokenizers, worst case 18.1% (T5), mean 27.5% |
| Both savings are stable at all scales | vs JSON 1.0-3.1pp range, vs TOON 1.0-4.3pp range per tokenizer |
| GCF has 94% fewer boundary merges than JSON | 43 tokenizers: GCF 0.47% vs JSON 8.17% (29,025 + 1,935 checks) |
| JSON merges compound at scale | "id" and "name" merge on 30% of tokenizers, repeating per row |
| GCF's adversarial surface is 24 words | Exhaustive vocab dump: pipe has 24 mergeable words vs quote 193 vs tab 1,238 |
| TOON tab merge is 71x worse than GCF pipe | TOON 32.91% vs GCF 0.47%. GPT-4o: 100% tab merge rate. Tab has 52x more mergeable words. |
| JSON overhead is 81% at 500 rows | Cross-tokenizer validated |
| JSON overhead grows linearly | O(n) per row, ratio 1,545:1 at 1000 rows |
| GCF savings are structural, not delimiter-specific | Grammar swap: 0.4pp spread across 5 delimiter sets, 800 measurements |
| JSON merges are hardcoded vocabulary entries | "name = #32586 on GPT-4. Exists in dictionary. Always selected. |
| GPT-4/4o have 1,000+ tab+letter vocab entries | TOON chose the worst possible delimiter for OpenAI models |
| GCF grammar is structurally equivalent | @ 100%, < 100%, | 99.2% isolation across 43 tokenizers. Grammar is deterministic. |
| JSON grammar fuses on every tokenizer | 92.5% of quote tokens are multi-grammar fusions ('":"', '","') on 43/43 tokenizers |
| Merges are irrecoverable | Can't fix with prompting, fine-tuning, or RLHF. Vocabulary is frozen. |
| JSON attention entropy crosses GCF at 50 orders | Pythia 410M: JSON 4.50 vs GCF 3.99 (+13%). Learned JSON parsing breaks down. |
| JSON grammar attention collapses at scale | Gemma 2B: grammar attention drops from 30% to 8.6% at 50+ orders. Model stops parsing. |
| This explains comprehension failures | 53.4% JSON at stress scale vs 91.2% GCF. Hidden boundaries + attention dilution. |
Reproduce
All experiments are reproducible:
# === Primary analysis (43 tokenizers, Python) ===
cd eval
python3 -m venv .venv && source .venv/bin/activate
pip install tokenizers huggingface_hub tiktoken
# 43-tokenizer: merge rates, vocab entries, savings vs JSON & TOON
python3 hf-tokenizer-analysis.py
# Structural equivalence proof (grammar isolation across 43 tokenizers)
python3 structural-equivalence-proof.py
# Exhaustive vocabulary dump (complete adversarial surface)
python3 adversarial-vocab-dump.py
# Attention mechanism analysis (Pythia 410M + Gemma 2B, requires torch + transformers)
pip install torch --index-url https://download.pytorch.org/whl/cpu transformers
python3 attention-analysis.py
# === Supplementary analyses (8 tokenizers, JS) ===
cd gcf # repo root
npm install @blackwell-systems/gcf @lenml/tokenizers \
@lenml/tokenizer-claude @lenml/tokenizer-gpt4 @lenml/tokenizer-gpt4o \
@lenml/tokenizer-llama3_1 @lenml/tokenizer-qwen2_5 \
@lenml/tokenizer-deepseek_v3 @lenml/tokenizer-gemma2 \
@lenml/tokenizer-mistral_nemo
# Syntactic deep dive (per-tokenizer token splits)
node eval/tokenizer-variance.mjs
# JSON overhead analysis (token distribution, scaling)
node eval/json-tokenization-analysis.mjs
# Worst-case JSON tokenization (maximum variance search)
node eval/worst-json-tokenization.mjs
# Grammar swap experiment (proves savings are structural)
node eval/grammar-swap-experiment.mjsWhat To Do About This
If your structured data enters LLM context windows at scale (100+ records), you have two options:
Use GCF. Encode with
encode_generic()before sending to the LLM. Decode withdecode_generic()afterward. Six language implementations, zero dependencies, drop-in.Keep using JSON and accept the consequences. Your most common field names (
id,name,type,value,title,time,text,url,path,description) have hidden structural boundaries on GPT-4, GPT-4o, LLaMA 3, Qwen, and Phi-4. This compounds per row. At 500 rows, you're asking the model to comprehend data through 1,500+ ambiguous token boundaries while 81% of its input is structural noise.
There is no option 3. You cannot fix JSON's tokenization without changing JSON's grammar, which would make it not JSON. And you cannot fix the tokenizer without retraining the model from scratch: the merged vocabulary entries ("name = #32586, "id = #29800, "type = #45570) are permanent, and all model weights depend on them.